

















preprints
- Côme Fiegel, Pierre Ménard, Tadashi Kozuno, Michal Valko, Vianney Perchet: Optimal last-iterate convergence in matrix games with bandit feedback using the log-barrier
arXiv preprint
bibtex abstract
We address the problem of minimax policy learning in zero-sum matrix games with bandit feedback. We demonstrate that employing log-barrier regularization with a dual-focused analysis achieves a convergence rate of $\tilde{O}(t^{-1/4})$ on the exploitability gap, matching the previously established lower bound. Our method extends to extensive-form games with equivalent performance guarantees.
- Yunhao Tang, Taco Cohen, David W. Zhang, Michal Valko, Rémi Munos: RL-finetuning LLMs from on- and off-policy data with a single algorithm
arXiv preprint
bibtex abstract
We introduce a novel reinforcement learning algorithm (AGRO, for Any-Generation Reward Optimization) for fine-tuning large-language models. AGRO leverages the concept of generation consistency, which states that the optimal policy satisfies the notion of consistency across any possible generation of the model. We derive algorithms that find optimal solutions via the sample-based policy gradient and provide theoretical guarantees on their convergence. Our experiments demonstrate the effectiveness of AGRO in both on-policy and off-policy settings, showing improved performance on the mathematical reasoning dataset over baseline algorithms.
- Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, Rémi Munos, Bernardo Ávila Pires, Michal Valko, Yong Cheng, Will Dabney: Understanding the performance gap between online and offline alignment algorithms
arXiv preprint
bibtex abstract
Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, rising popularity in offline alignment algorithms challenge the need for on-policy sampling in RLHF. Within the context of reward over-optimization, we start with an opening set of experiments that demonstrate the clear advantage of online methods over offline methods. This prompts us to investigate the causes to the performance discrepancy through a series of carefully designed experimental ablations. We show empirically that hypotheses such as offline data coverage and data quality by itself cannot convincingly explain the performance difference. We also find that while offline algorithms train policy to become good at pairwise classification, it is worse at generations; in the meantime the policies trained by online algorithms are good at generations while worse at pairwise classification. This hints at a unique interplay between discriminative and generative capabilities, which is greatly impacted by the sampling process. Lastly, we observe that the performance discrepancy persists for both contrastive and non-contrastive loss functions, and appears not to be addressed by simply scaling up policy networks. Taken together, our study sheds light on the pivotal role of on-policy sampling in AI alignment, and hints at certain fundamental challenges of offline alignment algorithms.
- Branislav Kveton, Zheng Wen, Azin Ashkan, Michal Valko: Learning to act greedily: Polymatroid semi-bandits, accepted with minor revisions to (JMLR)
bibtex
arXiv preprint abstract
Many important optimization problems, such as the minimum spanning tree and minimum-cost flow, can be solved optimally by a greedy method. In this work, we study a learning variant of these problems, where the model of the problem is unknown and has to be learned by interacting repeatedly with the environment in the bandit setting. We formalize our learning problem quite generally, as learning how to maximize an unknown modular function on a known polymatroid. We propose a computationally efficient algorithm for solving our problem and bound its expected cumulative regret. Our gap-dependent upper bound is tight up to a constant and our gap-free upper bound is tight up to polylogarithmic factors. Finally, we evaluate our method on three problems and demonstrate that it is practical.
- Antoine Scheid, Étienne Boursier, Alain Durmus, Michael I Jordan, Pierre Ménard, Éric Moulines, Michal Valko: Optimal design for reward modeling in RLHF
arXiv preprint
bibtex abstract
Reinforcement Learning from Human Feedback (RLHF) has become a popular approach to align language models (LMs) with human preferences. This method involves collecting a large dataset of human pairwise preferences across various text generations and using it to infer (implicitly or explicitly) a reward model. Numerous methods have been proposed to learn the reward model and align a LM with it. However, the costly process of collecting human preferences has received little attention and could benefit from theoretical insights. This paper addresses this issue and aims to formalize the reward training model in RLHF. We frame the selection of an effective dataset as a simple regret minimization task, using a linear contextual dueling bandit method. Given the potentially large number of arms, this approach is more coherent than the best-arm identification setting. We then propose an offline framework for solving this problem. Under appropriate assumptions, linearity of the reward model in the embedding space, and boundedness of the reward parameter, we derive bounds on the simple regret. Finally, we provide a lower bound that matches our upper bound up to constant and logarithmic terms. To our knowledge, this is the first theoretical contribution in this area to provide an offline approach as well as worst-case guarantees.
- Pierre Perrault, Denis Belomestny, Pierre Ménard, Éric Moulines, Alexey Naumov, Daniil Tiapkin, Michal Valko: A new bound on the cumulant generating function of Dirichlet processes
arXiv preprint
bibtex abstract
We introduce a novel approach for bounding the cumulant generating function (CGF) of a Dirichlet process (DP), using superadditivity. Our key technical contribution is the demonstration of the superadditivity of the log-moment generating function of the DP. This result, combined with Fekete's lemma and Varadhan's integral lemma, converts the known asymptotic large deviation principle into a practical upper bound on the CGF for any scale parameter. The bound is given by the convex conjugate of the scaled reversed Kullback-Leibler divergence. This new bound provides particularly effective confidence regions for sums of independent DPs, making it applicable across various fields.
- Denis Belomestny, Pierre Ménard, Alexey Naumov, Daniil Tiapkin, Michal Valko: Sharp deviations bounds for Dirichlet weighted sums with application to analysis of Bayesian algorithms
arXiv preprint
bibtex abstract
In this work, we derive sharp non-asymptotic deviation bounds for weighted sums of Dirichlet random variables. These bounds are based on a novel integral representation of the density of a weighted Dirichlet sum. This representation allows us to obtain a Gaussian-like approximation for the sum distribution using geometry and complex analysis methods. Our results generalize similar bounds for the Beta distribution obtained in the seminal paper Alfers and Dinges [1984]. Additionally, our results can be considered a sharp non-asymptotic version of the inverse of Sanov's theorem studied by Ganesh and O'Connell [1999] in the Bayesian setting. Based on these results, we derive new deviation bounds for the Dirichlet process posterior means with application to Bayesian bootstrap. Finally, we apply our estimates to the analysis of the Multinomial Thompson Sampling (TS) algorithm in multi-armed bandits and significantly sharpen the existing regret bounds by making them independent of the size of the arms distribution support.
- Tadashi Kozuno, Wenhao Yang, Nino Vieillard, Toshinori Kitamura, Yunhao Tang, Jincheng Mei, Pierre Ménard, Mohammad Gheshlaghi Azar, Michal Valko, Rémi Munos, Olivier Pietquin, Matthieu Geist, Csaba Szepesvári: KL-entropy-regularized RL with a generative model is minimax optimal
arXiv preprint
bibtex abstract
In this work, we consider and analyze the sample complexity of model-free reinforcement learning with a generative model. Particularly, we analyze mirror descent value iteration (MDVI) by Geist et al. (2019) and Vieillard et al. (2020a), which uses the Kullback-Leibler divergence and entropy regularization in its value and policy updates. Our analysis shows that it is nearly minimax-optimal for finding an $\varepsilon$-optimal policy when $\varepsilon$ is sufficiently small. This is the first theoretical result that demonstrates that a simple model-free algorithm without variance-reduction can be nearly minimax-optimal under the considered setting.
- Pierre Perrault, Jennifer Healey, Zheng Wen, Michal Valko: On the approximation relationship between optimizing ratio of submodular (RS) and difference of submodular (DS) functions
arXiv preprint
bibtex abstract
We demonstrate that from an algorithm guaranteeing an approximation factor for the ratio of submodular (RS) optimization problem, we can build another algorithm having a different kind of approximation guarantee -- weaker than the classical one -- for the difference of submodular (DS) optimization problem, and vice versa. We also illustrate the link between these two problems by analyzing a \textsc{Greedy} algorithm which approximately maximizes objective functions of the form $\Psi(f,g)$, where $f,g$ are two non-negative, monotone, submodular functions and $\Psi$ is a {quasiconvex} 2-variables function, which is non decreasing with respect to the first variable. For the choice $\Psi(f,g)\triangleq f/g$, we recover RS, and for the choice $\Psi(f,g)\triangleq f-g$, we recover DS. To the best of our knowledge, this greedy approach is new for DS optimization. For RS optimization, it reduces to the standard \textsc{GreedRatio} algorithm that has already been analyzed previously. However, our analysis is novel for this case.
2026
- Giorgio Racca, Michal Valko, Amartya Sanyal: Language generation with replay: A learning-theoretic view of model collapse, in International Conference on Machine Learning (ICML 2026) (LTW 2026 - oral)
arXiv preprint
OpenReview
bibtex
poster (image) abstract
As scaling laws push the training of frontier large language models (LLMs) toward ever-growing data requirements, training pipelines are approaching a regime where much of the publicly available online text may be consumed. At the same time, widespread LLM usage increases the volume of machine-generated content on the web; together, these trends raise the likelihood of generated text re-entering future training corpora, increasing the associated risk of performance degradation often called model collapse. In practice, model developers address this concern through data cleaning, watermarking, synthetic-data policies, or, in some cases, blissful ignorance. However, the problem of model collapse in generative models has not been examined from a learning-theoretic perspective: we study it through the theoretical lens of the language generation in the limit framework, introducing a replay adversary that augments the example stream with the generator's own past outputs. Our main contribution is a fine-grained learning-theoretic characterization of when replay fundamentally limits generation: while replay is benign for the strongest notion of uniform generation, it provably creates separations for the weaker notions of non-uniform generation and generation in the limit. Interestingly, our positive results mirror heuristics widely used in practice, such as data cleaning, watermarking, and output filtering, while our separations show when these ideas can fail.
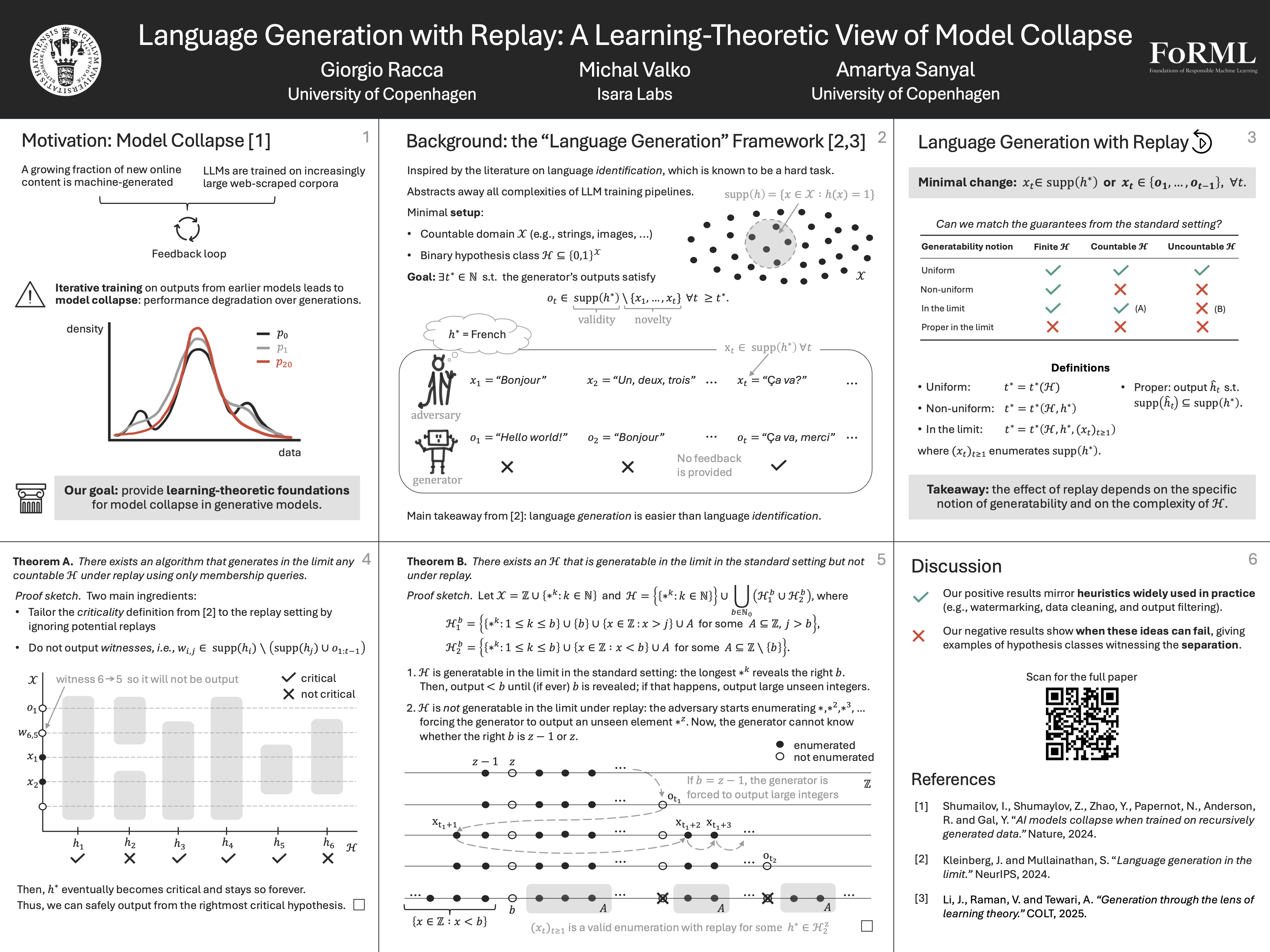{kind=link}
2025
- Côme Fiegel, Pierre Ménard, Tadashi Kozuno, Michal Valko, Vianney Perchet: The harder path: Last iterate convergence for uncoupled learning in zero-sum games with bandit feedback, in International Conference on Machine Learning (ICML 2025)
PDF
OpenReview
bibtex abstract
We study the problem of learning in zero-sum matrix games with repeated play and bandit feedback. Specifically, we focus on developing uncoupled algorithms that guarantee, without communication between players, the convergence of the last-iterate to a Nash equilibrium. Although the non-bandit case has been studied extensively, this setting has only been explored recently, with a bound of O(T^{-1/8}) on the exploitability gap. We show that, for uncoupled algorithms, guaranteeing convergence of the policy profiles to a Nash equilibrium is detrimental to the performance, with the best attainable rate being Omega(T^{-1/4}) in contrast to the usual Omega(T^{-1/2}) rate for convergence of the average iterates. We then propose two algorithms that achieve this optimal rate up to constant and logarithmic factors. The first algorithm leverages a straightforward trade-off between exploration and exploitation, while the second employs a regularization technique based on a two-step mirror descent approach.
- Daniil Tiapkin, Daniele Calandriello, Denis Belomestny, Éric Moulines, Alexey Naumov, Kashif Rasul, Michal Valko, Pierre Ménard: Proximal point Nash learning from human feedback, in COLT 2025 Workshop: Foundations of Post-training (COLT-FoPt 2025)
arXiv preprint
bibtex
poster abstract
Traditional Reinforcement Learning from Human Feedback (RLHF) often relies on reward models, frequently assuming preference structures like the Bradley-Terry model, which may not accurately capture the complexities of real human preferences (e.g., intransitivity). Nash Learning from Human Feedback (NLHF) offers a more direct alternative by framing the problem as finding a Nash equilibrium of a game defined by these preferences. While many works study the Nash learning problem directly in the policy space, we instead consider it under a more realistic policy parametrization setting. We first analyze a simple self-play policy gradient method, which is equivalent to Online IPO. We establish high-probability last-iterate convergence guarantees for this method, but our analysis also reveals a possible stability limitation of the underlying dynamics. Motivated by this, we embed the self-play updates into a proximal point framework, yielding a stabilized algorithm. For this combined method, we prove high-probability last-iterate convergence and discuss its more practical version, which we call Nash Prox. Finally, we apply this method to post-training of large language models and validate its empirical performance.
- Tianlin Liu, Shangmin Guo, Daniele Calandriello, Quentin Berthet, Felipe Llinares López, Jessica Hoffmann, Lucas Dixon, Michal Valko, Mathieu Blondel: Generation of an output token sequence from an input token sequence using two language model neural networks, International Patent WO2025166256A1 (2025) abstract
A method of using a first and a second language model neural network to generate an output token sequence from an input token sequence, where at least the second network has been fine-tuned. The method combines scores from both networks based on a realignment parameter to enable control over the degree of alignment at decoding time without requiring retraining.
- Daniel Jarrett, Corentin Tallec, Florent Altché, Thomas Mesnard, Rémi Munos, Michal Valko: Reinforcement learning using hindsight to model unpredictable aspects of the future, US Patent App. 18/238,400 (2025) abstract
Methods, systems, and apparatus, including computer programs encoded on computer storage media, for training a neural network using hindsight to model unpredictable aspects of the future in reinforcement learning.
- Chaoqi Wang, Zhuokai Zhao, Chen Zhu, Karthik Abinav Sankararaman, Michal Valko, Xuefei Cao, Zhaorun Chen, Madian Khabsa, Yuxin Chen, Hao Ma, Sinong Wang: Preference optimization with multi-sample comparisons, in International Conference on Learning Representations (ICLR 2025)
arXiv preprint
bibtex abstract
Traditional post-training approaches like RLHF rely on single-sample comparisons, which may not capture group-level characteristics like diversity and bias. We introduce Multi-sample Direct Preference Optimization (mDPO) and Multi-sample Identity Preference Optimization (mIPO), extending post-training to incorporate multi-sample comparisons focusing on group-wise attributes. Multi-sample comparisons are more effective than single-sample comparisons and offer a more robust optimization framework, particularly with label noise.
2024
- Llama Team: Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, ... Michal Valko ... Zef Rosnbrick, Zhaoduo Wen, Zhenyu Yang, Zhiwei Zhao, Zhiyu Ma: The Llama 3 herd of models, (arXiv 2024)
arXiv preprint
bibtex abstract
Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
- Aniket Didolkar, Anirudh Goyal, Nan Rosemary Ke, Siyuan Guo, Michal Valko, Timothy Lillicrap, Danilo Rezende, Yoshua Bengio, Michael Mozer, Sanjeev Arora: Metacognitive capabilities of LLMs: An exploration in mathematical problem solving, in Neural Information Processing Systems (NeurIPS 2024) (ICML 2024 - AI for Math)
arXiv preprint
poster
bibtex abstract
Metacognitive knowledge refers to humans' intuitive knowledge of their own thinking and reasoning processes. Today's best LLMs clearly possess some reasoning processes. The paper gives evidence that they also have metacognitive knowledge, including ability to name skills and procedures to apply given a task. We explore this primarily in context of math reasoning, developing a prompt-guided interaction procedure to get a powerful LLM to assign sensible skill labels to math questions, followed by having it perform semantic clustering to obtain coarser families of skill labels. These coarse skill labels look interpretable to humans. To validate that these skill labels are meaningful and relevant to the LLM's reasoning processes we perform the following experiments. (a) We ask GPT-4 to assign skill labels to training questions in math datasets GSM8K and MATH. (b) When using an LLM to solve the test questions, we present it with the full list of skill labels and ask it to identify the skill needed. Then it is presented with randomly selected exemplar solved questions associated with that skill label. This improves accuracy on GSM8k and MATH for several strong LLMs, including code-assisted models. The methodology presented is domain-agnostic, even though this article applies it to math problems.
- Côme Fiegel, Pierre Ménard, Tadashi Kozuno, Rémi Munos, Vianney Perchet, Michal Valko: Local and adaptive mirror descents in extensive-form games, in Neural Information Processing Systems (NeurIPS 2024)
arXiv preprint
bibtex abstract
We study how to learn $ε$-optimal strategies in zero-sum imperfect information games (IIG) with trajectory feedback. In this setting, players update their policies sequentially based on their observations over a fixed number of episodes, denoted by $T$. Existing procedures suffer from high variance due to the use of importance sampling over sequences of actions (Steinberger et al., 2020; McAleer et al., 2022). To reduce this variance, we consider a fixed sampling approach, where players still update their policies over time, but with observations obtained through a given fixed sampling policy. Our approach is based on an adaptive Online Mirror Descent (OMD) algorithm that applies OMD locally to each information set, using individually decreasing learning rates and a regularized loss. We show that this approach guarantees a convergence rate of $\tilde{\mathcal{O}}(T^{-1/2})$ with high probability and has a near-optimal dependence on the game parameters when applied with the best theoretical choices of learning rates and sampling policies. To achieve these results, we generalize the notion of OMD stabilization, allowing for time-varying regularization with convex increments.
- Rémi Munos*, Michal Valko, Daniele Calandriello*, Mohammad Gheshlaghi Azar*, Mark Rowland*, Daniel Guo*, Yunhao Tang*, Matthieu Geist*, Thomas Mesnard, Andrea Michi, Marco Selvi, Sertan Girgin, Nikola Momchev, Olivier Bachem, Daniel J. Mankowitz, Doina Precup, Bilal Piot: Nash learning from human feedback, in International Conference on Machine Learning (ICML 2024)
arXiv preprint
image
bibtex
talk abstract
Reinforcement learning from human feedback (RLHF) has emerged as the main paradigm for aligning large language models (LLMs) with human preferences. Typically, RLHF involves the initial step of learning a reward model from human feedback, often expressed as preferences between pairs of text generations produced by a pre-trained LLM. Subsequently, the LLM's policy is fine-tuned by optimizing it to maximize the reward model through a reinforcement learning algorithm. However, an inherent limitation of current reward models is their inability to fully represent the richness of human preferences and their dependency on the sampling distribution. In this study, we introduce an alternative pipeline for the fine-tuning of LLMs using pairwise human feedback. Our approach entails the initial learning of a preference model, which is conditioned on two inputs given a prompt, followed by the pursuit of a policy that consistently generates responses preferred over those generated by any competing policy, thus defining the Nash equilibrium of this preference model. We term this approach Nash learning from human feedback (NLHF). In the context of a tabular policy representation, we present a novel algorithmic solution, Nash-MD, founded on the principles of mirror descent. This algorithm produces a sequence of policies, with the last iteration converging to the regularized Nash equilibrium. Additionally, we explore parametric representations of policies and introduce gradient descent algorithms for deep-learning architectures. To demonstrate the effectiveness of our approach, we present experimental results involving the fine-tuning of a LLM for a text summarization task. We believe NLHF offers a compelling avenue for preference learning and policy optimization with the potential of advancing the field of aligning LLMs with human preferences.
- Daniele Calandriello, Daniel Guo, Rémi Munos, Mark Rowland, Yunhao Tang, Bernardo Ávila Pires, Pierre Harvey Richemond, Charline Le Lan, Michal Valko, Tianqi Liu, Rishabh Joshi, Zeyu Zheng, Bilal Piot: Human alignment of large language models through online preference optimisation, in International Conference on Machine Learning (ICML 2024) [spotlight - 3.5% acceptance rate]
arXiv preprint
bibtex abstract
Ensuring alignment of language models' outputs with human preferences is critical to guarantee a useful, safe, and pleasant user experience. Thus, human alignment has been extensively studied recently and several methods such as Reinforcement Learning from Human Feedback (RLHF), Direct Policy Optimisation (DPO) and Sequence Likelihood Calibration (SLiC) have emerged. In this paper, our contribution is two-fold. First, we show the equivalence between two recent alignment methods, namely Identity Policy Optimisation (IPO) and Nash Mirror Descent (Nash-MD). Second, we introduce a generalisation of IPO, named IPO-MD, that leverages the regularised sampling approach proposed by Nash-MD. This equivalence may seem surprising at first sight, since IPO is an offline method whereas Nash-MD is an online method using a preference model. However, this equivalence can be proven when we consider the online version of IPO, that is when both generations are sampled by the online policy and annotated by a trained preference model. Optimising the IPO loss with such a stream of data becomes then equivalent to finding the Nash equilibrium of the preference model through self-play. Building on this equivalence, we introduce the IPO-MD algorithm that generates data with a mixture policy (between the online and reference policy) similarly as the general Nash-MD algorithm. We compare online-IPO and IPO-MD to different online versions of existing losses on preference data such as DPO and SLiC on a summarisation task.
- Yunhao Tang, Zhaohan Daniel Guo, Zeyu Zheng, Daniele Calandriello, Rémi Munos, Mark Rowland, Pierre Harvey Richemond, Michal Valko, Bernardo Ávila Pires, Bilal Piot: Generalized preference optimization: A unified approach to offline alignment, in International Conference on Machine Learning (ICML 2024)
arXiv preprint
bibtex abstract
Offline preference optimization allows fine-tuning large models directly from offline data, and has proved effective in recent alignment practices. We propose generalized preference optimization (GPO), a family of offline losses parameterized by a general class of convex functions. GPO enables a unified view over preference optimization, encompassing existing algorithms such as DPO, IPO and SLiC as special cases, while naturally introducing new variants. The GPO framework also sheds light on how offline algorithms enforce regularization, through the design of the convex function that defines the loss. Our analysis and experiments reveal the connections and subtle differences between the offline regularization and the KL divergence regularization intended by the canonical RLHF formulation. In a controlled setting akin to Gao et al 2023, we also show that different GPO variants achieve similar trade-offs between regularization and performance, though the optimal values of hyper-parameter might differ as predicted by theory. In all, our results present new algorithmic toolkits and empirical insights to alignment practitioners.
- Tianlin Liu, Shangmin Guo, Leonardo Bianco, Daniele Calandriello, Quentin Berthet, Felipe Llinares, Jessica Hoffmann, Lucas Dixon, Michal Valko, Mathieu Blondel: Decoding-time realignment of language models, in International Conference on Machine Learning (ICML 2024) [spotlight - 3.5% acceptance rate]
arXiv preprint
bibtex abstract
Aligning language models with human preferences is crucial for reducing errors and biases in these models. Alignment techniques, such as reinforcement learning from human feedback (RLHF), are typically cast as optimizing a tradeoff between human preference rewards and a proximity regularization term that encourages staying close to the unaligned model. Selecting an appropriate level of regularization is critical: insufficient regularization can lead to reduced model capabilities due to reward hacking, whereas excessive regularization hinders alignment. Traditional methods for finding the optimal regularization level require retraining multiple models with varying regularization strengths. To address this challenge, we propose decoding-time realignment (DeRa), a simple method to explore and evaluate different regularization strengths in aligned models without retraining. DeRa enables control over the degree of alignment, allowing users to smoothly transition between unaligned and aligned models.
- Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Zhaohan Daniel Guo, Daniele Calandriello, Michal Valko, Rémi Munos: A general theoretical paradigm to understand learning from human preferences, in International Conference on Artificial Intelligence and Statistics (AISTATS 2024)
arXiv preprint
bibtex abstract
The prevalent deployment of learning from human preferences through reinforcement learning (RLHF) relies on two important approximations: the first assumes that pairwise preferences can be substituted with pointwise rewards. The second assumes that a reward model trained on these pointwise rewards can generalize from collected data to out-of-distribution data sampled by the policy. Recently, Direct Preference Optimisation (DPO) has been proposed as an approach that bypasses the second approximation and learn directly a policy from collected data without the reward modelling stage. However, this method still heavily relies on the first approximation. In this paper we try to gain a deeper theoretical understanding of these practical algorithms. In particular we derive a new general objective called ΨPO for learning from human preferences that is expressed in terms of pairwise preferences and therefore bypasses both approximations. This new general objective allows us to perform an in-depth analysis of the behavior of RLHF and DPO (as special cases of ΨPO) and to identify their potential pitfalls. We then consider another special case for ΨPO by setting Ψ simply to Identity, for which we can derive an efficient optimisation procedure, prove performance guarantees and demonstrate its empirical superiority to DPO on some illustrative examples.
- Alaa Saade, Steven Kapturowski, Daniele Calandriello, Charles Blundell, Pablo Sprechmann, Leopoldo Sarra, Oliver Groth, Michal Valko, Bilal Piot: Unlocking the power of representations in long-term novelty-based exploration, in International Conference on Learning Representations (ICLR 2024) (NeurIPS 2023 - ALOE) [spotlight - 5% acceptance rate]
arXiv preprint
bibtex abstract
We introduce Robust Exploration via Clustering-based Online Density Estimation (RECODE), a non-parametric method for novelty-based exploration that estimates visitation counts for clusters of states based on their similarity in a chosen embedding space. By adapting classical clustering to the nonstationary setting of Deep RL, RECODE can efficiently track state visitation counts over thousands of episodes. We further propose a novel generalization of the inverse dynamics loss, which leverages masked transformer architectures for multi-step prediction; which in conjunction with RECODE achieves a new state-of-the-art in a suite of challenging 3D-exploration tasks in DM-Hard-8. RECODE also sets new state-of-the-art in hard exploration Atari games, and is the first agent to reach the end screen in "Pitfall!".
- Daniil Tiapkin, Denis Belomestny, Daniele Calandriello, Éric Moulines, Alexey Naumov, Pierre Perrault, Michal Valko, Pierre Ménard: Demonstration-regularized RL, in International Conference on Learning Representations (ICLR 2024)
arXiv preprint
bibtex abstract
Incorporating expert demonstrations has empirically helped to improve the sample efficiency of reinforcement learning (RL). This paper quantifies theoretically to what extent this extra information reduces RL's sample complexity. In particular, we study the demonstration-regularized reinforcement learning that leverages the expert demonstrations by KL-regularization for a policy learned by behavior cloning. Our findings reveal that using $N^{\mathrm{E}}$ expert demonstrations enables the identification of an optimal policy at a sample complexity of order $\widetilde{O}(\mathrm{Poly}(S,A,H)/(\varepsilon^2 N^{\mathrm{E}}))$ in finite and $\widetilde{O}(\mathrm{Poly}(d,H)/(\varepsilon^2 N^{\mathrm{E}}))$ in linear Markov decision processes, where $\varepsilon$ is the target precision, $H$ the horizon, $A$ the number of action, $S$ the number of states in the finite case and $d$ the dimension of the feature space in the linear case. As a by-product, we provide tight convergence guarantees for the behaviour cloning procedure under general assumptions on the policy classes. Additionally, we establish that demonstration-regularized methods are provably efficient for reinforcement learning from human feedback (RLHF). In this respect, we provide theoretical evidence showing the benefits of KL-regularization for RLHF in tabular and linear MDPs. Interestingly, we avoid pessimism injection by employing computationally feasible regularization to handle reward estimation uncertainty, thus setting our approach apart from the prior works.
- Omar Darwiche Domingues, Yannis Flet-Berliac, Edouard Leurent, Pierre Ménard, Xuedong Shang, Michal Valko: rlberry: A reinforcement learning library for research and education, (Zenodo 2024)
GitHub
bibtex abstract
rlberry is a Python library for reinforcement learning (RL) designed for research and education. It provides a flexible and modular framework for implementing, evaluating, and comparing RL algorithms. The library supports various types of environments and agents, and includes tools for experiment management, reproducibility, and statistical analysis of results.
- Yunhao Tang, Rémi Munos, Mark Daniel Rowland, Michal Valko: Reinforcement learning by directly learning an advantage function, US Patent App. 18/424,520 (2024) abstract
A system and method of controlling an agent to take actions in an environment to perform a task by directly learning an advantage function through reinforcement learning.
{kind=link}
2023
- Daniil Tiapkin, Denis Belomestny, Daniele Calandriello, Éric Moulines, Rémi Munos, Alexey Naumov, Pierre Perrault, Michal Valko, Pierre Ménard: Model-free posterior sampling via learning rate randomization, in Neural Information Processing Systems (NeurIPS 2023)
arXiv preprint
bibtex abstract
In this paper, we introduce Randomized Q-learning (RandQL), a novel randomized model-free algorithm for regret minimization in episodic Markov Decision Processes (MDPs). To the best of our knowledge, RandQL is the first tractable model-free posterior sampling-based algorithm. We analyze the performance of RandQL in both tabular and non-tabular metric space settings. In tabular MDPs, RandQL achieves a regret bound of order $\widetilde{O}(\sqrt{H^{5}SAT})$, where $H$ is the planning horizon, $S$ is the number of states, $A$ is the number of actions, and $T$ is the number of episodes. For a metric state-action space, RandQL enjoys a regret bound of order $\widetilde{O}(H^{5/2} T^{(d_z+1)/(d_z+2)})$, where $d_z$ denotes the zooming dimension. Notably, RandQL achieves optimistic exploration without using bonuses, relying instead on a novel idea of learning rate randomization. Our empirical study shows that RandQL outperforms existing approaches on baseline exploration environments.
- Onno Eberhard, Thibaut Cuvelier, Michal Valko, Bruno Adrien De Backer: Middle-mile logistics through the lens of goal-conditioned reinforcement learning, in NeurIPS 2023 Workshop: Goal-conditioned RL (NeurIPS 2023 - GCRL)
OpenReview preprint
bibtex abstract
Middle-mile logistics describes the problem of routing parcels through a network of hubs linked by trucks with finite capacity. We rephrase this as a multi-object goal-conditioned MDP. Our method combines graph neural networks with model-free RL, extracting small feature graphs from the environment state.
- Daniel Jarrett, Corentin Tallec, Florent Altché, Thomas Mesnard, Rémi Munos, Michal Valko: Curiosity in hindsight: Intrinsic exploration in stochastic environments, in International Conference on Machine Learning (ICML 2023) (NeurIPS 2022 - DeepRL)
arXiv preprint
image
bibtex
talk abstract
Consider the problem of exploration in sparse-reward or reward-free environments, such as in Montezuma's Revenge. In the curiosity-driven paradigm, the agent is rewarded for how much each realized outcome differs from their predicted outcome. But using predictive error as intrinsic motivation is fragile in stochastic environments, as the agent may become trapped by high-entropy areas of the state-action space, such as a "noisy TV". In this work, we study a natural solution derived from structural causal models of the world: Our key idea is to learn representations of the future that capture precisely the unpredictable aspects of each outcome -- which we use as additional input for predictions, such that intrinsic rewards only reflect the predictable aspects of world dynamics. First, we propose incorporating such hindsight representations into models to disentangle "noise" from "novelty", yielding Curiosity in Hindsight: a simple and scalable generalization of curiosity that is robust to stochasticity. Second, we instantiate this framework for the recently introduced BYOL-Explore algorithm as our prime example, resulting in the noise-robust BYOL-Hindsight. Third, we illustrate its behavior under a variety of different stochasticities in a grid world, and find improvements over BYOL-Explore in hard-exploration Atari games with sticky actions. Notably, we show state-of-the-art results in exploring Montezuma's Revenge with sticky actions, while preserving performance in the non-sticky setting.
- Yunhao Tang, Rémi Munos, Mark Rowland, Michal Valko: VA-learning as a more efficient alternative to Q-learning, in International Conference on Machine Learning (ICML 2023)
arXiv preprint
bibtex abstract
In reinforcement learning, the advantage function is critical for policy improvement, but is often extracted from a learned Q-function. A natural question is: Why not learn the advantage function directly? In this work, we introduce VA-learning, which directly learns advantage function and value function using bootstrapping, without explicit reference to Q-functions. VA-learning learns off-policy and enjoys similar theoretical guarantees as Q-learning. Thanks to the direct learning of advantage function and value function, VA-learning improves the sample efficiency over Q-learning both in tabular implementations and deep RL agents on Atari-57 games. We also identify a close connection between VA-learning and the dueling architecture, which partially explains why a simple architectural change to DQN agents tends to improve performance.
- Daniil Tiapkin, Denis Belomestny, Daniele Calandriello, Éric Moulines, Rémi Munos, Alexey Naumov, Pierre Perrault, Yunhao Tang, Michal Valko, Pierre Ménard: Fast rates for maximum entropy exploration, in International Conference on Machine Learning (ICML 2023)
arXiv preprint
bibtex abstract
We address the challenge of exploration in reinforcement learning (RL) when the agent operates in an unknown environment with sparse or no rewards. In this work, we study the maximum entropy exploration problem of two different types. The first type is visitation entropy maximization previously considered by Hazan et al. (2019) in the discounted setting. For this type of exploration, we propose a game-theoretic algorithm that has sample complexity thus improving the epsilon-dependence upon existing results. The second type of entropy we study is the trajectory entropy. This objective function is closely related to the entropy-regularized MDPs, and we propose a simple algorithm that has a sample complexity of order polynomial in S, A, H over epsilon. Interestingly, it is the first theoretical result in RL literature that establishes the potential statistical advantage of regularized MDPs for exploration. Finally, we apply developed regularization techniques to reduce sample complexity of visitation entropy maximization, yielding a statistical separation between maximum entropy exploration and reward-free exploration.
- Côme Fiegel, Pierre Ménard, Tadashi Kozuno, Rémi Munos, Vianney Perchet, Michal Valko: Adapting to game trees in zero-sum imperfect information games, in International Conference on Machine Learning (ICML 2023) [outstanding paper award] [oral - 2% acceptance rate]
arXiv preprint
poster
poster (image)
talk
bibtex abstract
Imperfect information games (IIG) are games in which each player only partially observes the current game state. We study how to learn ε-optimal strategies in a zero-sum IIG through self-play with trajectory feedback. We give a problem-independent lower bound on the required number of realizations to learn these strategies with high probability, where H is the length of the game, A and B are the total number of actions for the two players. We also propose two Follow the Regularized leader (FTRL) algorithms for this setting: Balanced FTRL which matches this lower bound, but requires the knowledge of the information set structure beforehand to define the regularization; and Adaptive FTRL which needs more realizations without this requirement by progressively adapting the regularization to the observations.
- Yunhao Tang, Zhaohan Daniel Guo, Pierre Harvey Richemond, Bernardo Ávila Pires, Yash Chandak, Rémi Munos, Mark Rowland, Mohammad Gheshlaghi Azar, Charline Le Lan, Clare Lyle, András György, Shantanu Thakoor, Will Dabney, Bilal Piot, Daniele Calandriello, Michal Valko: Understanding self-predictive learning for reinforcement learning, in International Conference on Machine Learning (ICML 2023)
arXiv preprint
bibtex abstract
We study the learning dynamics of self-predictive learning for reinforcement learning, a family of algorithms that learn representations by minimizing the prediction error of their own future latent representations. Despite its recent empirical success, such algorithms have an apparent defect: trivial representations (such as constants) minimize the prediction error, yet it is obviously undesirable to converge to such solutions. Our central insight is that careful designs of the optimization dynamics are critical to learning meaningful representations. We identify that a faster paced optimization of the predictor and semi-gradient updates on the representation, are crucial to preventing the representation collapse. Then in an idealized setup, we show self-predictive learning dynamics carries out spectral decomposition on the state transition matrix, effectively capturing information of the transition dynamics. Building on the theoretical insights, we propose bidirectional self-predictive learning, a novel self-predictive algorithm that learns two representations simultaneously. We examine the robustness of our theoretical insights with a number of small-scale experiments and showcase the promise of the novel representation learning algorithm with large-scale experiments.
- Yunhao Tang, Tadashi Kozuno, Mark Rowland, Anna Harutyunyan, Rémi Munos, Bernardo Ávila Pires, Michal Valko: DoMo-AC: Doubly multi-step off-policy actor-critic algorithm, in International Conference on Machine Learning (ICML 2023)
arXiv preprint
bibtex abstract
Multi-step learning applies lookahead over multiple time steps and has proved valuable in policy evaluation settings. However, in the optimal control case, the impact of multi-step learning has been relatively limited despite a number of prior efforts. Fundamentally, this might be because multi-step policy improvements require operations that cannot be approximated by stochastic samples, hence hindering the widespread adoption of such methods in practice. To address such limitations, we introduce doubly multi-step off-policy VI (DoMo-VI), a novel oracle algorithm that combines multi-step policy improvements and policy evaluations. DoMo-VI enjoys guaranteed convergence speed-up to the optimal policy and is applicable in general off-policy learning settings. We then propose doubly multi-step off-policy actor-critic (DoMo-AC), a practical instantiation of the DoMo-VI algorithm. DoMo-AC introduces a bias-variance trade-off that ensures improved policy gradient estimates. When combined with the IMPALA architecture, DoMo-AC has showed improvements over the baseline algorithm on Atari-57 game benchmarks.
- Toshinori Kitamura, Tadashi Kozuno, Yunhao Tang, Nino Vieillard, Michal Valko, Wenhao Yang, Jincheng Mei, Pierre Ménard, Mohammad Gheshlaghi Azar, Rémi Munos, Olivier Pietquin, Matthieu Geist, Csaba Szepesvári, Wataru Kumagai: Regularization and variance-weighted regression achieves minimax optimality in linear MDPs: Theory and practice, in International Conference on Machine Learning (ICML 2023)
pdf
arXiv preprint
bibtex abstract
Mirror descent value iteration (MDVI), an abstraction of Kullback-Leibler (KL) and entropy-regularized reinforcement learning (RL), has served as the basis for recent high-performing practical RL algorithms. However, despite the use of function approximation in practice, the theoretical understanding of MDVI has been limited to tabular Markov decision processes (MDPs). We study MDVI with linear function approximation through its sample complexity required to identify an ε-optimal policy with probability 1-δ under the settings of an infinite-horizon linear MDP, generative model, and G-optimal design. We demonstrate that least-squares regression weighted by the variance of an estimated optimal value function of the next state is crucial to achieving minimax optimality. Based on this observation, we present Variance-Weighted Least-Squares MDVI (VWLS-MDVI), the first theoretical algorithm that achieves nearly minimax optimal sample complexity for infinite-horizon linear MDPs. Furthermore, we propose a practical VWLS algorithm for value-based deep RL, Deep Variance Weighting (DVW). Our experiments demonstrate that DVW improves the performance of popular value-based deep RL algorithms on a set of MinAtar benchmarks.
- Thomas Mesnard, Wenqi Chen, Alaa Saade, Yunhao Tang, Mark Rowland, Theophane Weber, Clare Lyle, Audrunas Gruslys, Michal Valko, Will Dabney, Georg Ostrovski, Éric Moulines, Rémi Munos: Quantile credit assignment, in International Conference on Machine Learning (ICML 2023) [oral - 2% acceptance rate]
PMLR proceedings
bibtex abstract
In reinforcement learning, the credit assignment problem is to distinguish luck from skill, that is, separate the inherent randomness in the environment from the controllable effects of the agent's actions. This paper proposes two novel algorithms, Quantile Credit Assignment (QCA) and Hindsight QCA (HQCA), which incorporate distributional value estimation to perform credit assignment. QCA uses a network that predicts the quantiles of the return distribution, whereas HQCA additionally incorporates information about the future. Both QCA and HQCA have the appealing interpretation of leveraging an estimate of the quantile level of the return (interpreted as the level of "luck") in order to derive a "luck-dependent" baseline for policy gradient methods. We show theoretically that this approach gives an unbiased policy gradient estimator that can yield significant variance reductions over a standard value estimate baseline. QCA and HQCA significantly outperform prior state-of-the-art methods on a range of extremely difficult credit assignment problems.
- Mehdi Azabou, Venkataramana Ganesh, Shantanu Thakoor, Chi-Heng Lin, Lakshmi Sathidevi, Ran Liu, Michal Valko, Petar Veličković, Eva L Dyer: Half-Hop: A graph upsampling approach for slowing down message passing, in International Conference on Machine Learning (ICML 2023)
arXiv preprint
bibtex
poster
code abstract
Message passing neural networks have shown a lot of success on graph-structured data. However, there are many instances where message passing can lead to over-smoothing or fail when neighboring nodes belong to different classes. In this work, we introduce a simple yet general framework for improving learning in message passing neural networks. Our approach essentially upsamples edges in the original graph by adding "slow nodes" at each edge that can mediate communication between a source and a target node. Our method only modifies the input graph, making it plug-and-play and easy to use with existing models. To understand the benefits of slowing down message passing, we provide theoretical and empirical analyses. We report results on several supervised and self-supervised benchmarks, and show improvements across the board, notably in heterophilic conditions where adjacent nodes are more likely to have different labels. Finally, we show how our approach can be used to generate augmentations for self-supervised learning, where slow nodes are randomly introduced into different edges in the graph to generate multi-scale views with variable path lengths.
- Alaa Saade, Steven Kapturowski, Daniele Calandriello, Charles Blundell, Michal Valko, Pablo Sprechmann, Bilal Piot: Reinforcement learning using density estimation with online clustering for exploration, International Patent App. PCT/EP2023/076893 (2023) abstract
A method for exploration in reinforcement learning that combines online clustering with density estimation to compute novelty-based intrinsic rewards, enabling agents to efficiently track state visitation counts across thousands of episodes in sparse-reward environments.
{kind=link}
{kind=link}
2022
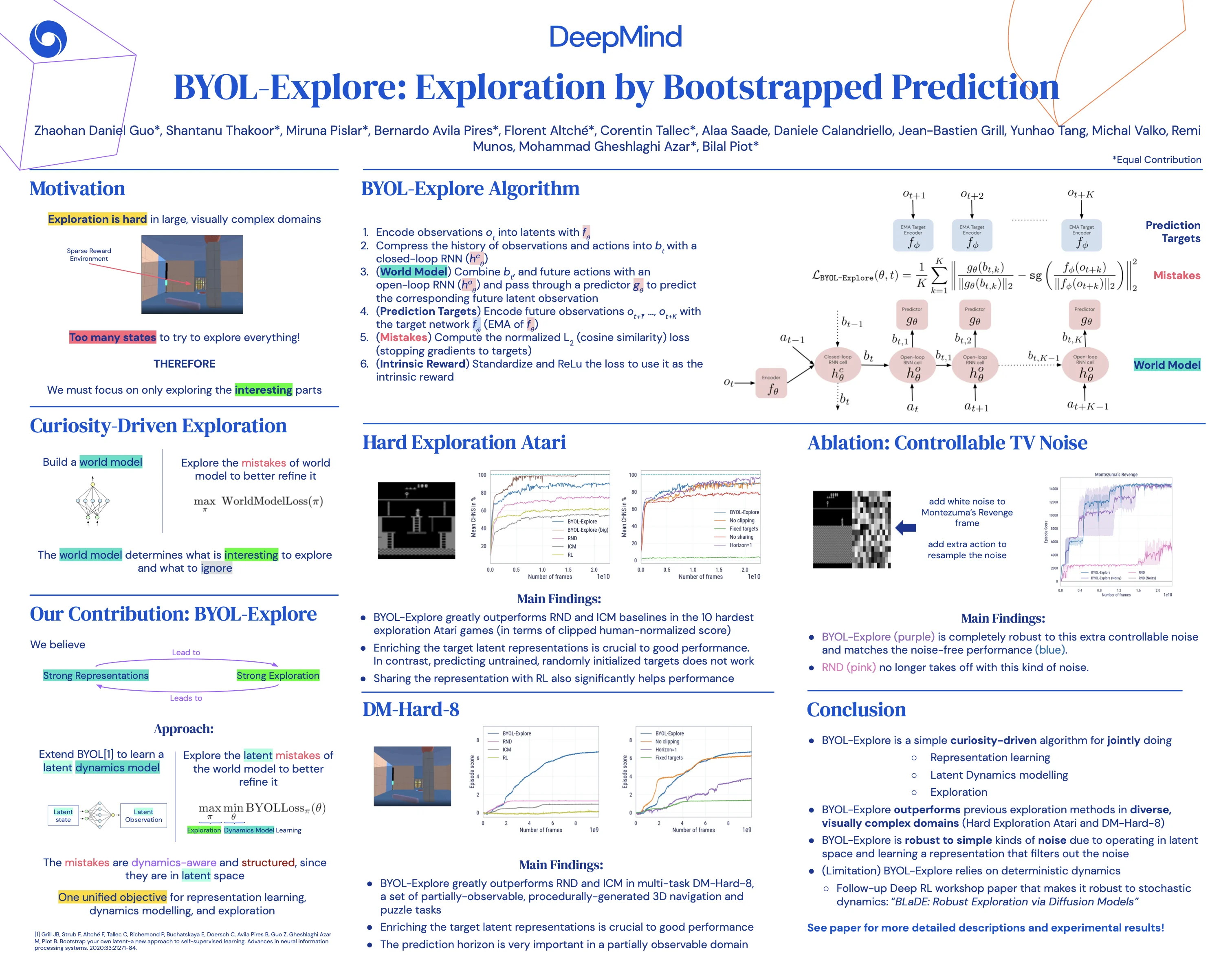
- Zhaohan Daniel Guo, Shantanu Thakoor, Miruna Pîslar, Bernardo Ávila Pires, Florent Altché, Corentin Tallec, Alaa Saade, Daniele Calandriello, Jean-Bastien Grill, Yunhao Tang, Michal Valko, Rémi Munos, Mohammad Gheshlaghi Azar, Bilal Piot: BYOL-Explore: Exploration by bootstrapped prediction, in Neural Information Processing Systems (NeurIPS 2022)
arXiv preprint
poster
bibtex abstract
We present BYOL-Explore, a conceptually simple yet general approach for curiosity-driven exploration in visually-complex environments. BYOL-Explore learns a world representation, the world dynamics, and an exploration policy all-together by optimizing a single prediction loss in the latent space with no additional auxiliary objective. We show that BYOL-Explore is effective in DM-HARD-8, a challenging partially-observable continuous-action hard-exploration benchmark with visually-rich 3-D environments. On this benchmark, we solve the majority of the tasks purely through augmenting the extrinsic reward with BYOL-Explore's intrinsic reward, whereas prior work could only get off the ground with human demonstrations. As further evidence of the generality of BYOL-Explore, we show that it achieves superhuman performance on the ten hardest exploration games in Atari while having a much simpler design than other competitive agents.
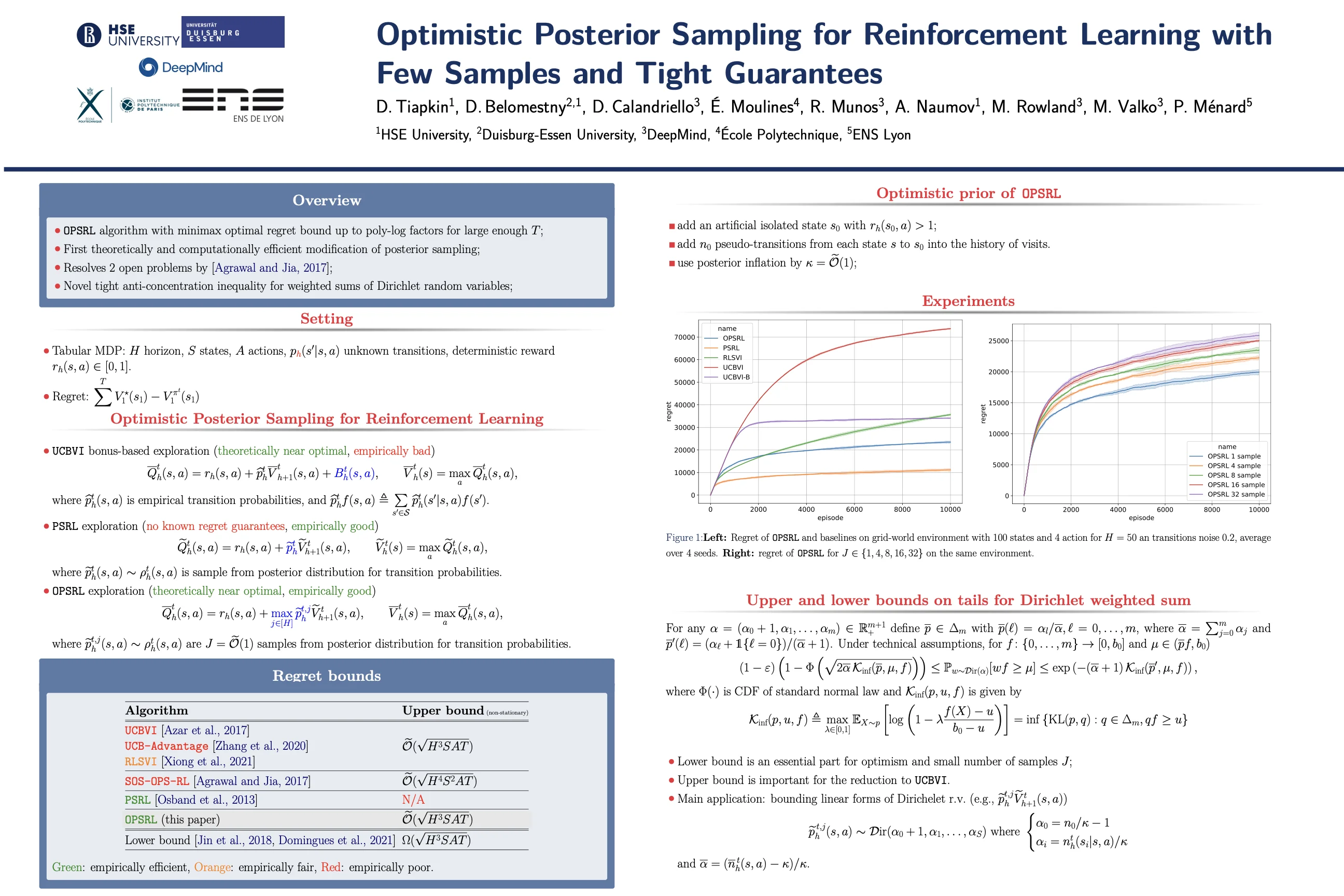
poster (image) talk - Daniil Tiapkin, Denis Belomestny, Daniele Calandriello, Éric Moulines, Rémi Munos, Alexey Naumov, Mark Rowland, Michal Valko, Pierre Ménard: Optimistic posterior sampling for reinforcement learning with few samples and tight guarantees, in Neural Information Processing Systems (NeurIPS 2022)
arXiv preprint
poster
poster (image)
talk
bibtex abstract
We consider reinforcement learning in an environment modeled by an episodic, finite, stage-dependent Markov decision process of horizon H with S states, and A actions. The performance of an agent is measured by the regret after interacting with the environment for T episodes. We propose an optimistic posterior sampling algorithm for reinforcement learning (OPSRL), a simple variant of posterior sampling that only needs a number of posterior samples logarithmic in H, S, A, and T per state-action pair. For OPSRL we guarantee a high-probability regret bound of order at most O(sqrt(H^3 SAT)) ignoring poly log(HSAT) terms. The key novel technical ingredient is a new sharp anti-concentration inequality for linear forms which may be of independent interest. Specifically, we extend the normal approximation-based lower bound for Beta distributions by Alfers and Dinges (1984) to Dirichlet distributions. Our bound matches the lower bound of order Omega(sqrt(H^3 SAT)), thereby answering the open problems raised by Agrawal and Jia (2017b) for the episodic setting.
- Daniil Tiapkin, Denis Belomestny, Éric Moulines, Alexey Naumov, Sergey Samsonov, Yunhao Tang, Michal Valko, Pierre Ménard: From Dirichlet to Rubin: Optimistic exploration in RL without bonuses, in International Conference on Machine Learning (ICML 2022) [long talk - 2% acceptance rate]
arXiv preprint
talk
poster
bibtex abstract
We propose the Bayes-UCBVI algorithm for reinforcement learning in tabular, stage-dependent, episodic Markov decision process: a natural extension of the Bayes-UCB algorithm by Kaufmann et al. (2012) for multi-armed bandits. Our method uses the quantile of a Q-value function posterior as upper confidence bound on the optimal Q-value function. For Bayes-UCBVI, we prove a regret bound of order $\widetilde{O}(\sqrt{H^3SAT})$ where $H$ is the length of one episode, $S$ is the number of states, $A$ the number of actions, $T$ the number of episodes, that matches the lower-bound of $Ω(\sqrt{H^3SAT})$ up to poly-$\log$ terms in $H,S,A,T$ for a large enough $T$. To the best of our knowledge, this is the first algorithm that obtains an optimal dependence on the horizon $H$ (and $S$) without the need for an involved Bernstein-like bonus or noise. Crucial to our analysis is a new fine-grained anti-concentration bound for a weighted Dirichlet sum that can be of independent interest. We then explain how Bayes-UCBVI can be easily extended beyond the tabular setting, exhibiting a strong link between our algorithm and Bayesian bootstrap (Rubin, 1981).
- Anirudh Goyal, Abram L Friesen, Theophane Weber, Andrea Banino, Nan Rosemary Ke, Adrià Puigdomènech Badia, Ksenia Konyushkova, Michal Valko, Simon Osindero, Timothy P Lillicrap, Nicolas Heess, Charles Blundell: Retrieval-augmented reinforcement learning, in International Conference on Machine Learning (ICML 2022)
arXiv preprint
bibtex abstract
Most deep reinforcement learning (RL) algorithms distill experience into parametric behavior policies or value functions via gradient updates. While effective, this approach has several disadvantages: (1) it is computationally expensive, (2) it can take many updates to integrate experiences into the parametric model, (3) experiences that are not fully integrated do not appropriately influence the agent's behavior, and (4) behavior is limited by the capacity of the model. In this paper we explore an alternative paradigm in which we train a network to map a dataset of past experiences to optimal behavior. Specifically, we augment an RL agent with a retrieval process (parameterized as a neural network) that has direct access to a dataset of experiences. This dataset can come from the agent's past experiences, expert demonstrations, or any other relevant source. The retrieval process is trained to retrieve information from the dataset that may be useful in the current context, to help the agent achieve its goal faster and more efficiently. We integrate our method into two different RL agents: an offline DQN agent and an online R2D2 agent. In offline multi-task problems, we show that the retrieval-augmented DQN agent avoids task interference and learns faster than the baseline DQN agent. On Atari, we show that retrieval-augmented R2D2 learns significantly faster than the baseline R2D2 agent and achieves higher scores.
- Daniele Calandriello, Luigi Carratino, Alessandro Lazaric, Michal Valko, Lorenzo Rosasco: Scaling Gaussian process optimization by evaluating a few unique candidates multiple times, in International Conference on Machine Learning (ICML 2022)
arXiv preprint
talk
poster
bibtex abstract
Computing a Gaussian process (GP) posterior has a computational cost cubical in the number of historical points. A reformulation of the same GP posterior highlights that this complexity mainly depends on how many unique historical points are considered. This can have important implication in active learning settings, where the set of historical points is constructed sequentially by the learner. We show that sequential black-box optimization based on GPs (GP-Opt) can be made efficient by sticking to a candidate solution for multiple evaluation steps and switch only when necessary. Limiting the number of switches also limits the number of unique points in the history of the GP. Thus, the efficient GP reformulation can be used to exactly and cheaply compute the posteriors required to run the GP-Opt algorithms. This approach is especially useful in real-world applications of GP-Opt with high switch costs (e.g., switching chemicals in wet labs, data/model loading in hyperparameter optimization). As examples of this meta-approach, we modify two well-established GP-Opt algorithms, GP-UCB and GP-EI, to switch candidates as infrequently as possible adapting rules from batched GP-Opt. These versions preserve all the theoretical no-regret guarantees while improving practical aspects of the algorithms such as runtime, memory complexity, and the ability of batching candidates and evaluating them in parallel.
- Shantanu Thakoor, Corentin Tallec, Mohammad Gheshlaghi Azar, Mehdi Azabou, Eva L. Dyer, Rémi Munos, Petar Veličković, Michal Valko: Large-scale representation learning on graphs via bootstrapping, in International Conference on Learning Representations (ICLR 2022) (ICLR 2021 - GTRL)
arXiv preprint
poster
bibtex
talk abstract
Self-supervised learning provides a promising path towards eliminating the need for costly label information in representation learning on graphs. However, to achieve state-of-the-art performance, methods often need large numbers of negative examples and rely on complex augmentations. This can be prohibitively expensive, especially for large graphs. To address these challenges, we introduce Bootstrapped Graph Latents (BGRL) - a graph representation learning method that learns by predicting alternative augmentations of the input. BGRL uses only simple augmentations and alleviates the need for contrasting with negative examples, and is thus scalable by design. BGRL outperforms or matches prior methods on several established benchmarks, while achieving a 2-10x reduction in memory costs. Furthermore, we show that BGRL can be scaled up to extremely large graphs with hundreds of millions of nodes in the semi-supervised regime - achieving state-of-the-art performance and improving over supervised baselines where representations are shaped only through label information. In particular, our solution centered on BGRL constituted one of the winning entries to the Open Graph Benchmark - Large Scale Challenge at KDD Cup 2021, on a graph orders of magnitudes larger than all previously available benchmarks, thus demonstrating the scalability and effectiveness of our approach.
- Jean Tarbouriech, Omar Darwiche Domingues, Pierre Ménard, Matteo Pirotta, Michal Valko, Alessandro Lazaric: Adaptive multi-goal exploration, in International Conference on Artificial Intelligence and Statistics (AISTATS 2022)
arXiv preprint
bibtex abstract
We introduce a generic strategy for provably efficient multi-goal exploration. It relies on AdaGoal, a novel goal selection scheme that leverages a measure of uncertainty in reaching states to adaptively target goals that are neither too difficult nor too easy. We show how AdaGoal can be used to tackle the objective of learning an $ε$-optimal goal-conditioned policy for the (initially unknown) set of goal states that are reachable within $L$ steps in expectation from a reference state $s_0$ in a reward-free Markov decision process. In the tabular case with $S$ states and $A$ actions, our algorithm requires $\tilde{O}(L^3 S A ε^{-2})$ exploration steps, which is nearly minimax optimal. We also readily instantiate AdaGoal in linear mixture Markov decision processes, yielding the first goal-oriented PAC guarantee with linear function approximation. Beyond its strong theoretical guarantees, we anchor AdaGoal in goal-conditioned deep reinforcement learning, both conceptually and empirically, by connecting its idea of selecting "uncertain" goals to maximizing value ensemble disagreement.
- Yunhao Tang, Mark Rowland, Rémi Munos, Michal Valko: Marginalized operators for off-policy reinforcement learning, in International Conference on Artificial Intelligence and Statistics (AISTATS 2022) (ICML 2021 - RL Theory)
arXiv preprint
bibtex abstract
In this work, we propose marginalized operators, a new class of off-policy evaluation operators for reinforcement learning. Marginalized operators strictly generalize generic multi-step operators, such as Retrace, as special cases. Marginalized operators also suggest a form of sample-based estimates with potential variance reduction, compared to sample-based estimates of the original multi-step operators. We show that the estimates for marginalized operators can be computed in a scalable way, which also generalizes prior results on marginalized importance sampling as special cases. Finally, we empirically demonstrate that marginalized operators provide performance gains to off-policy evaluation and downstream policy optimization algorithms.
{kind=link}
{kind=link}
2021
- Ran Liu, Mehdi Azabou, Max Dabagia, Chi-Heng Lin, Mohammad Gheshlaghi Azar, Keith B. Hengen, Michal Valko, Eva L. Dyer: Drop, swap, and generate: A self-supervised approach for generating neural activity, in Neural Information Processing Systems (NeurIPS 2021) [oral - 1% acceptance rate]
arXiv preprint
bibtex abstract
Meaningful and simplified representations of neural activity can yield insights into how and what information is being processed within a neural circuit. However, without labels, finding representations that reveal the link between the brain and behavior can be challenging. Here, we introduce a novel unsupervised approach for learning disentangled representations of neural activity called Swap-VAE. Our approach combines a generative modeling framework with an instance-specific alignment loss that tries to maximize the representational similarity between transformed views of the input (brain state). These transformed (or augmented) views are created by dropping out neurons and jittering samples in time, which intuitively should lead the network to a representation that maintains both temporal consistency and invariance to the specific neurons used to represent the neural state. Through evaluations on both synthetic data and neural recordings from hundreds of neurons in different primate brains, we show that it is possible to build representations that disentangle neural datasets along relevant latent dimensions linked to behavior.
- Jean Tarbouriech, Runlong Zhou, Simon S. Du, Matteo Pirotta, Michal Valko, Alessandro Lazaric: Stochastic shortest path: Minimax, parameter-free and towards horizon-free regret, in Neural Information Processing Systems (NeurIPS 2021) (ICML 2021 - RL Theory) [spotlight - 3% acceptance rate]
arXiv preprint
talk
poster (image)
video
bibtex abstract
We study the problem of learning in the stochastic shortest path (SSP) setting, where an agent seeks to minimize the expected cost accumulated before reaching a goal state. We design a novel model-based algorithm EB-SSP that carefully skews the empirical transitions and perturbs the empirical costs with an exploration bonus to induce an optimistic SSP problem whose associated value iteration scheme is guaranteed to converge. We prove that EB-SSP achieves the minimax regret rate $\tilde{O}(B_{\star} \sqrt{S A K})$, where $K$ is the number of episodes, $S$ is the number of states, $A$ is the number of actions, and $B_{\star}$ bounds the expected cumulative cost of the optimal policy from any state, thus closing the gap with the lower bound. Interestingly, EB-SSP obtains this result while being parameter-free, i.e., it does not require any prior knowledge of $B_{\star}$, nor of $T_{\star}$, which bounds the expected time-to-goal of the optimal policy from any state. Furthermore, we illustrate various cases (e.g., positive costs, or general costs when an order-accurate estimate of $T_{\star}$ is available) where the regret only contains a logarithmic dependence on $T_{\star}$, thus yielding the first (nearly) horizon-free regret bound beyond the finite-horizon MDP setting.
- Jean Tarbouriech, Matteo Pirotta, Michal Valko, Alessandro Lazaric: A provably efficient sample collection strategy for reinforcement learning, in Neural Information Processing Systems (NeurIPS 2021) [spotlight - 3% acceptance rate]
arXiv preprint
bibtex abstract
A common assumption in reinforcement learning (RL) is to have access to a generative model (i.e., a simulator of the environment), which allows to generate samples from any desired state-action pair. Nonetheless, in many settings a generative model may not be available and an adaptive exploration strategy is needed to efficiently collect samples from an unknown environment by direct interaction. In this paper, we study the scenario where an algorithm based on the generative model assumption defines the (possibly time-varying) amount of samples b(s,a) required at each state-action pair (s,a) and an exploration strategy has to learn how to generate b(s,a) samples as fast as possible. Building on recent results for regret minimization in the stochastic shortest path (SSP) setting (Cohen et al., 2020; Tarbouriech et al., 2020), we derive an algorithm that requires O(BD+D3/2S2A) time steps to collect the B=∑s,ab(s,a) desired samples, in any unknown and communicating MDP with S states, A actions and diameter D. Leveraging the generality of our strategy, we readily apply it to a variety of existing settings (e.g., model estimation, pure exploration in MDPs) for which we obtain improved sample-complexity guarantees, and to a set of new problems such as best-state identification and sparse reward discovery.
- Tadashi Kozuno*, Pierre Ménard*, Rémi Munos, Michal Valko: Model-free learning for two-player zero-sum partially observable Markov games with perfect recall, in Neural Information Processing Systems (NeurIPS 2021)
arXiv preprint
talk
poster
bibtex abstract
We study the problem of learning a Nash equilibrium (NE) in an imperfect information game (IIG) through self-play. Precisely, we focus on two-player, zero-sum, episodic, tabular IIG under the perfect-recall assumption where the only feedback is realizations of the game (bandit feedback). In particular, the dynamic of the IIG is not known -- we can only access it by sampling or interacting with a game simulator. For this learning setting, we provide the Implicit Exploration Online Mirror Descent (IXOMD) algorithm. It is a model-free algorithm with a high-probability bound on the convergence rate to the NE of order 1/sqrt(T) where T is the number of played games. Moreover, IXOMD is computationally efficient as it needs to perform the updates only along the sampled trajectory.
- Yunhao Tang*, Tadashi Kozuno*, Mark Rowland, Rémi Munos, Michal Valko: Unifying gradient estimators for meta-reinforcement learning via off-policy evaluation, in Neural Information Processing Systems (NeurIPS 2021)
arXiv preprint
bibtex abstract
Model-agnostic meta-reinforcement learning requires estimating the Hessian matrix of value functions. This is challenging from an implementation perspective, as repeatedly differentiating policy gradient estimates may lead to biased Hessian estimates. In this work, we provide a unifying framework for estimating higher-order derivatives of value functions, based on off-policy evaluation. Our framework interprets a number of prior approaches as special cases and elucidates the bias and variance trade-off of Hessian estimates. This framework also opens the door to a new family of estimates, which can be easily implemented with auto-differentiation libraries, and lead to performance gains in practice.
- Adrià Recasens, Pauline Luc, Jean-Baptiste Alayrac, Luyu Wang, Florian Strub, Corentin Tallec, Mateusz Malinowski, Viorica Patraucean, Florent Altché, Michal Valko, Jean-Bastien Grill, Aäron van den Oord, Andrew Zisserman: Broaden your views for self-supervised video learning, in International Conference on Computer Vision (ICCV 2021)
arXiv preprint
poster
bibtex abstract
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
- Pierre Ménard, Omar Darwiche Domingues, Xuedong Shang, Michal Valko: UCB momentum Q-learning: Correcting the bias without forgetting, in International Conference on Machine Learning (ICML 2021) [long talk - 3% acceptance rate]
arXiv preprint
poster
poster (image)
talk
bibtex abstract
We propose UCBMQ, Upper Confidence Bound Momentum Q-learning, a new algorithm for reinforcement learning in tabular and possibly stage-dependent, episodic Markov decision process. UCBMQ is based on Q-learning where we add a momentum term and rely on the principle of optimism in face of uncertainty to deal with exploration. Our new technical ingredient of UCBMQ is the use of momentum to correct the bias that Q-learning suffers while, at the same time, limiting the impact it has on the second-order term of the regret. For UCBMQ, we are able to guarantee a regret of at most $O(\sqrt{H^3SAT}+ H^4 S A )$ where $H$ is the length of an episode, $S$ the number of states, $A$ the number of actions, $T$ the number of episodes and ignoring terms in poly-$\log(SAHT)$. Notably, UCBMQ is the first algorithm that simultaneously matches the lower bound of $Ω(\sqrt{H^3SAT})$ for large enough $T$ and has a second-order term (with respect to the horizon $T$) that scales only linearly with the number of states $S$.
- Pierre Ménard, Omar Darwiche Domingues, Émilie Kaufmann, Anders Jonsson, Édouard Leurent, Michal Valko: Fast active learning for pure exploration in reinforcement learning, in International Conference on Machine Learning (ICML 2021)
arXiv preprint
bibtex abstract
Realistic environments often provide agents with very limited feedback. When the environment is initially unknown, the feedback, in the beginning, can be completely absent, and the agents may first choose to devote all their effort on exploring efficiently. The exploration remains a challenge while it has been addressed with many hand-tuned heuristics with different levels of generality on one side, and a few theoretically backed exploration strategies on the other. Many of them are incarnated by intrinsic motivation and in particular explorations bonuses. A common rule of thumb for exploration bonuses is to use 1/n‾√ bonus that is added to the empirical estimates of the reward, where n is a number of times this particular state (or a state-action pair) was visited. We show that, surprisingly, for a pure-exploration objective of reward-free exploration, bonuses that scale with 1/n bring faster learning rates, improving the known upper bounds with respect to the dependence on the horizon H. Furthermore, we show that with an improved analysis of the stopping time, we can improve by a factor H the sample complexity in the best-policy identification setting, which is another pure-exploration objective, where the environment provides rewards but the agent is not penalized for its behavior during the exploration phase.
- Tadashi Kozuno, Yunhao Tang, Mark Rowland, Rémi Munos, Steven Kapturowski, Will Dabney, Michal Valko, David Abel: Revisiting Peng's Q(λ) for modern reinforcement learning, in International Conference on Machine Learning (ICML 2021)
arXiv preprint
bibtex abstract
Off-policy multi-step reinforcement learning algorithms consist of conservative and non-conservative algorithms: the former actively cut traces, whereas the latter do not. Recently, Munos et al. (2016) proved the convergence of conservative algorithms to an optimal Q-function. In contrast, non-conservative algorithms are thought to be unsafe and have a limited or no theoretical guarantee. Nonetheless, recent studies have shown that non-conservative algorithms empirically outperform conservative ones. Motivated by the empirical results and the lack of theory, we carry out theoretical analyses of Peng's Q($\lambda$), a representative example of non-conservative algorithms. We prove that it also converges to an optimal policy provided that the behavior policy slowly tracks a greedy policy in a way similar to conservative policy iteration. Such a result has been conjectured to be true but has not been proven. We also experiment with Peng's Q($\lambda$) in complex continuous control tasks, confirming that Peng's Q($\lambda$) often outperforms conservative algorithms despite its simplicity. These results indicate that Peng's Q($\lambda$), which was thought to be unsafe, is a theoretically-sound and practically effective algorithm.
- Yunhao Tang, Mark Rowland, Rémi Munos, Michal Valko: Taylor expansion of discount factors, in International Conference on Machine Learning (ICML 2021)
arXiv preprint
bibtex abstract
In practical reinforcement learning (RL), the discount factor used for estimating value functions often differs from that used for defining the evaluation objective. In this work, we study the effect that this discrepancy of discount factors has during learning, and discover a family of objectives that interpolate value functions of two distinct discount factors. Our analysis suggests new ways for estimating value functions and performing policy optimization updates, which demonstrate empirical performance gains. This framework also leads to new insights on commonly-used deep RL heuristic modifications to policy optimization algorithms.
- Xavier Fontaine, Pierre Perrault, Michal Valko, Vianney Perchet: Online A-optimal design and active linear regression, in International Conference on Machine Learning (ICML 2021)
arXiv preprint
bibtex abstract
We consider in this paper the problem of optimal experiment design where a decision maker can choose which points to sample to obtain an estimate of the hidden parameter of an underlying linear model. The key challenge of this work lies in the heteroscedasticity assumption that we make, meaning that each covariate has a different and unknown variance. The goal of the decision maker is then to figure out on the fly the optimal way to allocate the total budget of T samples between covariates, as sampling several times a specific one will reduce the variance of the estimated model around it (but at the cost of a possible higher variance elsewhere). By trying to minimize the l2-loss the decision maker is actually minimizing the trace of the covariance matrix of the problem, which corresponds then to online A-optimal design. Combining techniques from bandit and convex optimization we propose a new active sampling algorithm and we compare it with existing ones. We provide theoretical guarantees of this algorithm in different settings, including a O(T^{-2}) regret bound in the case where the covariates form a basis of the feature space, generalizing and improving existing results. Numerical experiments validate our theoretical findings.
- Omar Darwiche Domingues, Pierre Ménard, Matteo Pirotta, Émilie Kaufmann, Michal Valko: Kernel-based reinforcement learning: A finite-time analysis, in International Conference on Machine Learning (ICML 2021)
arXiv preprint
bibtex abstract
We consider the exploration-exploitation dilemma in finite-horizon reinforcement learning problems whose state-action space is endowed with a metric. We introduce Kernel-UCBVI, a model-based optimistic algorithm that leverages the smoothness of the MDP and a non-parametric kernel estimator of the rewards and transitions to efficiently balance exploration and exploitation. For problems with K episodes and horizon H, we provide a regret bound of O(H^3 K^{2d/(2d+1)}), where d is the covering dimension of the joint state-action space. This is the first regret bound for kernel-based RL using smoothing kernels, which requires very weak assumptions on the MDP and has been previously applied to a wide range of tasks. We empirically validate our approach in continuous MDPs with sparse rewards.
- Karl Tuyls, Shayegan Omidshafiei, Paul Muller, Zhe Wang, Jerome Connor, Daniel Hennes, Ian Graham, William Spearman, Tim Waskett, Dafydd Steele, Pauline Luc, Adrià Recasens, Alexandre Galashov, Gregory Thornton, Romuald Elie, Pablo Sprechmann, Pol Moreno, Kris Cao, Marta Garnelo, Praneet Dutta, Michal Valko, Nicolas Heess, Alex Bridgland, Julien Pérolat, Bart De Vylder, Ali Eslami, Mark Rowland, Andrew Jaegle, Rémi Munos, Trevor Back, Razia Ahamed, Simon Bouton, Nathalie Beauguerlange, Jackson Broshear, Thore Graepel, Demis Hassabis: Game plan: What AI can do for football, and what football can do for AI, in Journal of Artificial Intelligence Research (JAIR 2021)
arXiv preprint
bibtex abstract
The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).
- Omar Darwiche Domingues, Pierre Ménard, Matteo Pirotta, Émilie Kaufmann, Michal Valko: A kernel-based approach to non-stationary reinforcement learning in metric spaces, in International Conference on Artificial Intelligence and Statistics (AISTATS 2021) (ICML 2020 - RL Theory) [oral - 6% acceptance rate]
arXiv preprint
bibtex
video abstract
In this work, we propose KeRNS, an algorithm for episodic reinforcement learning in non-stationary Markov Decision Processes (MDPs) whose state-action set is endowed with a metric. Using a non-parametric model of the MDP built with time-dependent kernels, we prove a regret bound that scales with the covering dimension of the state-action space and the total variation of the MDP with time, which quantifies its level of non-stationarity. Our method generalizes previous approaches based on sliding windows and exponential discounting used to handle changing environments. We further propose a practical implementation of KeRNS, we analyze its regret and validate it experimentally.
- Omar Darwiche Domingues, Pierre Ménard, Émilie Kaufmann, Michal Valko: Episodic reinforcement learning in finite MDPs: Minimax lower bounds revisited, in Algorithmic Learning Theory (ALT 2021)
arXiv preprint
video
bibtex abstract
In this paper, we propose new problem-independent lower bounds on the sample complexity and regret in episodic MDPs, with a particular focus on the non-stationary case in which the transition kernel is allowed to change in each stage of the episode. Our main contribution is a lower bound of Omega((H^3SA/epsilon^2)log(1/delta)) on the sample complexity of an (epsilon,delta)-PAC algorithm for best policy identification in a non-stationary MDP, relying on a construction of "hard MDPs" which is different from the ones previously used in the literature. Using this same class of MDPs, we also provide a rigorous proof of the Omega(sqrt(H^3SAT)) regret bound for non-stationary MDPs. Finally, we discuss connections to PAC-MDP lower bounds.
- Jean Tarbouriech, Matteo Pirotta, Michal Valko, Alessandro Lazaric: Sample complexity bounds for stochastic shortest path with a generative model, in Algorithmic Learning Theory (ALT 2021)
video
bibtex abstract
We consider the objective of computing an epsilon-optimal policy in a stochastic shortest path (SSP) setting, provided that we can access a generative sampling oracle. We propose two algorithms for this setting and derive PAC bounds on their sample complexity: one for the case of positive costs and the other for the case of non-negative costs under a restricted optimality criterion. While tight sample complexity bounds have been derived for the finite-horizon and discounted MDPs, the SSP problem is a strict generalization of these settings and it poses additional technical challenges due to the fact that no specific time horizon is prescribed and policies may never terminate, i.e., we are possibly facing non-proper policies. As a consequence, we can neither directly apply existing techniques minimizing sample complexity nor rely on a regret-to-PAC conversion leveraging recent regret bounds for SSP. Our analysis instead combines SSP-specific tools and variance reduction techniques to obtain the first sample complexity bounds for this setting.
- Émilie Kaufmann, Pierre Ménard, Omar Darwiche Domingues, Anders Jonsson, Édouard Leurent, Michal Valko: Adaptive reward-free exploration, in Algorithmic Learning Theory (ALT 2021) (ICML 2020 - RL Theory)
arXiv preprint
video 1
video 2
bibtex abstract
Reward-free exploration is a reinforcement learning setting recently studied by Jin et al., who address it by running several algorithms with regret guarantees in parallel. In our work, we instead propose a more adaptive approach for reward-free exploration which directly reduces upper bounds on the maximum MDP estimation error. We show that, interestingly, our reward-free UCRL algorithm can be seen as a variant of an algorithm of Fiechter from 1994, originally proposed for a different objective that we call best-policy identification. We prove that RF-UCRL needs O((SAH4/$\epsilon$2)ln(1/$\delta$)) episodes to output, with probability 1−$\delta$, an $\epsilon$-approximation of the optimal policy for any reward function. We empirically compare it to oracle strategies using a generative model.
- Guillaume Gautier, Rémi Bardenet, Michal Valko: Fast sampling from β-ensembles, (Statistics and Computing 2021)
arXiv preprint
bibtex abstract
We study sampling algorithms for $\beta$-ensembles with time complexity less than cubic in the cardinality of the ensemble. Following Dumitriu and Edelman (2002), we see the ensemble as the eigenvalues of a random tridiagonal matrix, namely a random Jacobi matrix. First, we provide a unifying and elementary treatment of the tridiagonal models associated to the three classical Hermite, Laguerre and Jacobi ensembles. For this purpose, we use simple changes of variables between successive reparametrizations of the coefficients defining the tridiagonal matrix. Second, we derive an approximate sampler for the simulation of $\beta$-ensembles, and illustrate how fast it can be for polynomial potentials. This method combines a Gibbs sampler on Jacobi matrices and the diagonalization of these matrices. In practice, even for large ensembles, only a few Gibbs passes suffice for the marginal distribution of the eigenvalues to fit the expected theoretical distribution. When the conditionals in the Gibbs sampler can be simulated exactly, the same fast empirical convergence is observed for the fluctuations of the largest eigenvalue. Our experimental results support a conjecture by Krishnapur et al. (2016), that the Gibbs chain on Jacobi matrices of size N mixes in O(log(N)).
- Mehdi Azabou, Mohammad Gheshlaghi Azar, Ran Liu, Chi-Heng Lin, Erik C. Johnson, Kiran Bhaskaran-Nair, Max Dabagia, Bernardo Ávila Pires, Lindsey Kitchell, Keith B. Hengen, William Gray-Roncal, Michal Valko, Eva L. Dyer: Mine Your Own vieW: Self-supervised learning through across-sample prediction, in NeurIPS Workshop on Self-Supervised Learning - Theory and Practice (NeurIPS-W 2021)
arXiv preprint
bibtex abstract
State-of-the-art methods for self-supervised learning (SSL) build representations by maximizing the similarity between different augmented "views" of a sample. Because these approaches try to match views of the same sample, they can be too myopic and fail to produce meaningful results when augmentations are not sufficiently rich. This motivates the use of the dataset itself to find similar, yet distinct, samples to serve as views for one another. In this paper, we introduce Mine Your Own vieW (MYOW), a new approach for building across-sample prediction into SSL. The idea behind our approach is to actively mine views, finding samples that are close in the representation space of the network, and then predict, from one sample's latent representation, the representation of a nearby sample. In addition to showing the promise of MYOW on standard datasets used in computer vision, we highlight the power of this idea in a novel application in neuroscience where rich augmentations are not already established. When applied to neural datasets, MYOW outperforms other self-supervised approaches in all examples (in some cases by more than 10{\%}), and surpasses the supervised baseline for most datasets. By learning to predict the latent representation of similar samples, we show that it is possible to learn good representations in new domains where augmentations are still limited.
- Omar Darwiche Domingues, Corentin Tallec, Rémi Munos, Michal Valko: Density-based bonuses on learned representations for reward-free exploration in deep reinforcement learning, in ICML 2021 Workshop: Unsupervised Reinforcement Learning (ICML 2021 - URL)
OpenReview
bibtex abstract
In this paper, we study the problem of representation learning and exploration in reinforcement learning. We propose a framework to compute exploration bonuses based on density estimation, that can be used with any representation learning method, and that allows the agent to explore without extrinsic rewards. In the special case of tabular Markov decision processes (MDPs), this approach mimics the behavior of theoretically sound algorithms. In continuous and partially observable MDPs, the same approach can be applied by learning a latent representation, on which a probability density is estimated.
- Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Alaa Saade, Shantanu Thakoor, Bilal Piot, Bernardo Ávila Pires, Michal Valko, Thomas Mesnard, Tor Lattimore, Rémi Munos: Geometric entropic exploration, in Journal of Machine Learning Research (JMLR 2025 and ICML 2021 - URL)
ICML 2021 Workshop: Unsupervised Reinforcement Learning
arXiv preprint
bibtex abstract
Exploration is essential for solving complex Reinforcement Learning (RL) tasks. Maximum State-Visitation Entropy (MSVE) formulates the exploration problem as a well-defined policy optimization problem whose solution aims at visiting all states as uniformly as possible. This is in contrast to standard uncertainty-based approaches where exploration is transient and eventually vanishes. However, existing approaches to MSVE are theoretically justified only for discrete state-spaces as they are oblivious to the geometry of continuous domains. We address this challenge by introducing Geometric Entropy Maximisation (GEM), a new algorithm that maximises the geometry-aware Shannon entropy of state-visits in both discrete and continuous domains. Our key theoretical contribution is casting geometry-aware MSVE exploration as a tractable problem of optimising a simple and novel noise-contrastive objective function. In our experiments, we show the efficiency of GEM in solving several RL problems with sparse rewards, compared against other deep RL exploration approaches.
- Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Bernardo Ávila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Rémi Munos, Michal Valko: Self-supervised representation learning using bootstrapped latent representations, US Patent App. 17/338,777 (2021) abstract
Training a target encoder neural network to generate representations of images using a self-supervised approach based on bootstrapping latent representations, without requiring negative pairs or specialized architectures.
{kind=link}
{kind=link}
2020
- Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Ávila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, Rémi Munos, Michal Valko: Bootstrap Your Own Latent: A new approach to self-supervised learning, in Neural Information Processing Systems (NeurIPS 2020) [oral - 1% acceptance rate]
arXiv preprint
bibtex
talk abstract
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the-art methods rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches 74.3% top-1 classification accuracy on ImageNet using a linear evaluation with a ResNet-50 architecture and 79.6% with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks. Our implementation and pretrained models are given on GitHub.
- Pierre H. Richemond, Jean-Bastien Grill, Florent Altché, Corentin Tallec, Florian Strub, Andrew Brock, Samuel Smith, Soham De, Razvan Pascanu, Bilal Piot, Michal Valko: BYOL works even without batch statistics, in NeurIPS Workshop on Self-Supervised Learning - Theory and Practice (NeurIPS-W 2020)
arXiv preprint
bibtex abstract
Bootstrap Your Own Latent (BYOL) is a self-supervised learning approach for image representation. From an augmented view of an image, BYOL trains an online network to predict a target network representation of a different augmented view of the same image. Unlike contrastive methods, BYOL does not explicitly use a repulsion term built from negative pairs in its training objective. Yet, it avoids collapse to a trivial, constant representation. Thus, it has recently been hypothesized that batch normalization (BN) is critical to prevent collapse in BYOL. Indeed, BN flows gradients across batch elements, and could leak information about negative views in the batch, which could act as an implicit negative (contrastive) term. However, we experimentally show that replacing BN with a batch-independent normalization scheme (namely, a combination of group normalization and weight standardization) achieves performance comparable to vanilla BYOL ({\$}73.9\backslash{\%}{\$} vs. {\$}74.3\backslash{\%}{\$} top-1 accuracy under the linear evaluation protocol on ImageNet with ResNet-{\$}50{\$}). Our finding disproves the hypothesis that the use of batch statistics is a crucial ingredient for BYOL to learn useful representations.
- Jean Tarbouriech, Matteo Pirotta, Michal Valko, Alessandro Lazaric: Improved sample complexity for incremental autonomous exploration in MDPs, in Neural Information Processing Systems (NeurIPS 2020) [oral - 1% acceptance rate]
arXiv preprint
poster
image
bibtex abstract
We investigate the exploration of an unknown environment when no reward function is provided. Building on the incremental exploration setting introduced by Lim and Auer [1], we define the objective of learning the set of ϵ-optimal goal-conditioned policies attaining all states that are incrementally reachable within L steps (in expectation) from a reference state s0. In this paper, we introduce a novel model-based approach that interleaves discovering new states from s0 and improving the accuracy of a model estimate that is used to compute goal-conditioned policies to reach newly discovered states. The resulting algorithm, DisCo, achieves a sample complexity scaling as Õ (L5SL+ϵ$\Gamma$L+ϵAϵ−2), where A is the number of actions, SL+ϵ is the number of states that are incrementally reachable from s0 in L+ϵ steps, and $\Gamma$L+ϵ is the branching factor of the dynamics over such states. This improves over the algorithm proposed in [1] in both ϵ and L at the cost of an extra $\Gamma$L+ϵ factor, which is small in most environments of interest. Furthermore, DisCo is the first algorithm that can return an ϵ/cmin-optimal policy for any cost-sensitive shortest-path problem defined on the L-reachable states with minimum cost cmin. Finally, we report preliminary empirical results confirming our theoretical findings.
- Daniele Calandriello*, Michał Dereziński*, Michal Valko: Sampling from a k-DPP without looking at all items, in Neural Information Processing Systems (NeurIPS 2020) [spotlight - 3% acceptance rate]
arXiv preprint
bibtex abstract
Determinantal point processes (DPPs) are a useful probabilistic model for selecting a small diverse subset out of a large collection of items, with applications in summarization, stochastic optimization, active learning and more. Given a kernel function and a subset size k, our goal is to sample k out of n items with probability proportional to the determinant of the kernel matrix induced by the subset (a.k.a. k-DPP). Existing k-DPP sampling algorithms require an expensive preprocessing step which involves multiple passes over all n items, making it infeasible for large datasets. A na{\"{i}}ve heuristic addressing this problem is to uniformly subsample a fraction of the data and perform k-DPP sampling only on those items, however this method offers no guarantee that the produced sample will even approximately resemble the target distribution over the original dataset. In this paper, we develop an algorithm which adaptively builds a sufficiently large uniform sample of data that is then used to efficiently generate a smaller set of k items, while ensuring that this set is drawn exactly from the target distribution defined on all n items. We show empirically that our algorithm produces a k-DPP sample after observing only a small fraction of all elements, leading to several orders of magnitude faster performance compared to the state-of-the-art.
- Pierre Perrault, Étienne Boursier, Vianney Perchet, Michal Valko: Statistical efficiency of Thompson sampling for combinatorial semi-bandits, in Neural Information Processing Systems (NeurIPS 2020)
arXiv preprint
bibtex abstract
We investigate stochastic combinatorial multi-armed bandit with semi-bandit feedback (CMAB). In CMAB, the question of the existence of an efficient policy with an optimal asymptotic regret (up to a factor poly-logarithmic with the action size) is still open for many families of distributions, including mutually independent outcomes, and more generally the multivariate sub-Gaussian family. We propose to answer the above question for these two families by analyzing variants of the Combinatorial Thompson Sampling policy (CTS). For mutually independent outcomes in [0,1] , we propose a tight analysis of CTS using Beta priors. We then look at the more general setting of multivariate sub-Gaussian outcomes and propose a tight analysis of CTS using Gaussian priors. This last result gives us an alternative to the Efficient Sampling for Combinatorial Bandit policy (ESCB), which, although optimal, is not computationally efficient.
- Anders Jonsson, Émilie Kaufmann, Pierre Ménard, Omar Darwiche Domingues, Édouard Leurent, Michal Valko: Planning in Markov decision processes with gap-dependent sample complexity, in Neural Information Processing Systems (NeurIPS 2020)
arXiv preprint
poster
bibtex abstract
We propose MDP-GapE, a new trajectory-based Monte-Carlo Tree Search algorithm for planning in a Markov Decision Process in which transitions have a finite support. We prove an upper bound on the number of calls to the generative models needed for MDP-GapE to identify a near-optimal action with high probability. This problem-dependent sample complexity result is expressed in terms of the sub-optimality gaps of the state-action pairs that are visited during exploration. Our experiments reveal that MDP-GapE is also effective in practice, in contrast with other algorithms with sample complexity guarantees in the fixed-confidence setting, that are mostly theoretical.
- Jean-Bastien Grill, Florent Altché, Yunhao Tang, Thomas Hubert, Michal Valko, Ioannis Antonoglou, Rémi Munos: Monte-Carlo tree search as regularized policy optimization, in International Conference on Machine Learning (ICML 2020)
talk
image
arXiv preprint
video
bibtex abstract
The combination of Monte-Carlo tree search (MCTS) with deep reinforcement learning has led to groundbreaking results in artificial intelligence. However, AlphaZero, the current state-of-the-art MCTS algorithm still relies on handcrafted heuristics that are only partially understood. In this paper, we show that AlphaZero's search heuristic, along with other common ones, can be interpreted as an approximation to the solution of a specific regularized policy optimization problem. With this insight, we propose a variant of AlphaZero which uses the exact solution to this policy optimization problem, and show experimentally that it reliably outperforms the original algorithm in multiple domains.
- Yunhao Tang, Michal Valko, Rémi Munos: Taylor expansion policy optimization, in International Conference on Machine Learning (ICML 2020) (MS RL Day 2021)
arXiv preprint
talk
image
bibtex abstract
In this work, we investigate the application of Taylor expansions in reinforcement learning. In particular, we propose Taylor expansion policy optimization, a policy optimization formalism that generalizes prior work (e.g., TRPO) as a first-order special case. We also show that Taylor expansions intimately relate to off-policy evaluation. Finally, we show that this new formulation entails modifications which improve the performance of several state-of-the-art distributed algorithms.
- Rémy Degenne, Pierre Ménard, Xuedong Shang, Michal Valko: Gamification of pure exploration for linear bandits, in International Conference on Machine Learning (ICML 2020)
arXiv preprint
talk
bibtex abstract
We investigate an active pure-exploration setting, that includes best-arm identification, in the context of linear stochastic bandits. While asymptotically optimal algorithms exist for standard multi-arm bandits, the existence of such algorithms for the best-arm identification in linear bandits has been elusive despite several attempts to address it. First, we provide a thorough comparison and new insight over different notions of optimality in the linear case, including G-optimality, transductive optimality from optimal experimental design and asymptotic optimality. Second, we design the first asymptotically optimal algorithm for fixed-confidence pure exploration in linear bandits. As a consequence, our algorithm naturally bypasses the pitfall caused by a simple but difficult instance, that most prior algorithms had to be engineered to deal with explicitly. Finally, we avoid the need to fully solve an optimal design problem by providing an approach that entails an efficient implementation.
- Pierre Perrault, Zheng Wen, Jennifer Healey, Michal Valko: Budgeted online influence maximization, in International Conference on Machine Learning (ICML 2020)
video
bibtex abstract
We introduce a new budgeted framework for online influence maximization, considering the total cost of an advertising campaign instead of the common cardinality constraint on a chosen influencer set. Our approach models better the real-world setting where the cost of influencers varies and advertisers want to find the best value for their overall social advertising budget. We propose an algorithm assuming an independent cascade diffusion model and edge-level semi-bandit feedback, and provide both theoretical and experimental results. Our analysis is also valid for the cardinality-constraint setting and improves the state of the art regret bound in this case.
- Jean Tarbouriech, Evrard Garcelon, Michal Valko, Matteo Pirotta, Alessandro Lazaric: No-regret exploration in goal-oriented reinforcement learning, in International Conference on Machine Learning (ICML 2020)
arXiv preprint
talk
bibtex abstract
Many popular reinforcement learning problems (e.g., navigation in a maze, some Atari games, mountain car) are instances of the episodic setting under its stochastic shortest path (SSP) formulation, where an agent has to achieve a goal state while minimizing the cumulative cost. Despite the popularity of this setting, the exploration-exploitation dilemma has been sparsely studied in general SSP problems, with most of the theoretical literature focusing on different problems (i.e., fixed-horizon and infinite-horizon) or making the restrictive loop-free SSP assumption (i.e., no state can be visited twice during an episode). In this paper, we study the general SSP problem with no assumption on its dynamics (some policies may actually never reach the goal). We introduce UC-SSP, the first no-regret algorithm in this setting, and prove a regret bound scaling as O(DSsqrt(ADK)) after K episodes for any unknown SSP with S states, A actions, positive costs and SSP-diameter D, defined as the smallest expected hitting time from any starting state to the goal. We achieve this result by crafting a novel stopping rule, such that UC-SSP may interrupt the current policy if it is taking too long to achieve the goal and switch to alternative policies that are designed to rapidly terminate the episode.
- Aadirupa Saha, Pierre Gaillard, Michal Valko: Improved sleeping bandits with stochastic action sets and adversarial rewards, in International Conference on Machine Learning (ICML 2020)
arXiv preprint
talk
bibtex abstract
In this paper, we consider the problem of sleeping bandits with stochastic action sets and adversarial rewards. In this setting, in contrast to most work in bandits, the actions may not be available at all times. For instance, some products might be out of stock in item recommendation. The best existing efficient (i.e., polynomial-time) algorithms for this problem only guarantee a O(T**2/3) upper-bound on the regret. Yet, inefficient algorithms based on EXP4 can achieve O(sqrt(T)). In this paper, we provide a new computationally efficient algorithm inspired by EXP3 satisfying a regret of order O(sqrt(T)) when the availabilities of each action i in A are independent. We then study the most general version of the problem where at each round available sets are generated from some unknown arbitrary distribution (i.e., without the independence assumption) and propose an efficient algorithm with O(sqrt(2**KT)) regret guarantee. Our theoretical results are corroborated with experimental evaluations.
- Anne Manegueu, Claire Vernade, Alexandra Carpentier, Michal Valko: Stochastic bandits with arm-dependent delays, in International Conference on Machine Learning (ICML 2020) (GPSD 2020) (WiML 2019)
arXiv preprint
video
bibtex abstract
Significant work has been recently dedicated to the stochastic delayed bandit setting because of its relevance in applications. The applicability of existing algorithms is however restricted by the fact that strong assumptions are often made on the delay distributions, such as full observability, restrictive shape constraints, or uniformity over arms. In this work, we weaken them significantly and only assume that there is a bound on the tail of the delay. In particular, we cover the important case where the delay distributions vary across arms, and the case where the delays are heavy-tailed. Addressing these difficulties, we propose a simple but efficient UCB-based algorithm called the PATIENTBANDITS. We provide both problem-dependent and problem-independent bounds on the regret as well as performance lower bounds.
- Daniele Calandriello, Luigi Carratino, Alessandro Lazaric, Michal Valko, Lorenzo Rosasco: Near-linear time Gaussian process optimization with adaptive batching and resparsification, in International Conference on Machine Learning (ICML 2020) (OPT 2019)
arXiv preprint
talk
bibtex abstract
Gaussian processes (GP) are one of the most successful frameworks to model uncertainty. However , GP optimization (e.g., GP-UCB) suffers from major scalability issues. Experimental time grows linearly with the number of evaluations, unless candidates are selected in batches (e.g., using GP-BUCB) and evaluated in parallel. Furthermore , computational cost is often prohibitive since algorithms such as GP-BUCB require a time at least quadratic in the number of dimensions and iterations to select each batch. In this paper, we introduce BBKB (Batch Budgeted Kernel Bandits), the first no-regret GP optimization algorithm that provably runs in near-linear time and selects candidates in batches. This is obtained with a new guarantee for the tracking of the posterior variances that allows BBKB to choose increasingly larger batches, improving over GP-BUCB. Moreover , we show that the same bound can be used to adaptively delay costly updates to the sparse GP approximation used by BBKB, achieving a near-constant per-step amortized cost. These findings are then confirmed in several experiments, where BBKB is much faster than state-of-the-art methods.
- Pierre Perrault, Vianney Perchet, Michal Valko: Covariance-adapting algorithm for semi-bandits with application to sparse rewards, in Conference on Learning Theory (COLT 2020)
arXiv preprint
video
bibtex abstract
We investigate stochastic combinatorial semi-bandits, where the entire joint distribution of rewards impacts the complexity of the problem instance (unlike in the standard bandits). Typical distributions considered depend on specific parameter values, whose prior knowledge is required in theory but quite difficult to estimate in practice; an example is the commonly assumed sub-Gaussian family. We alleviate this issue by instead considering a new general family of sub-exponential distributions, which contains bounded and Gaussian ones. We prove a new lower bound on the expected regret on this family, that is parameterized by the unknown covariance matrix of rewards, a tighter quantity than the sub-Gaussian matrix. We then construct an algorithm that uses covariance estimates, and provide a tight asymptotic analysis of the regret. Finally, we apply and extend our results to the family of sparse rewards, which has applications in many recommender systems.
- Xuedong Shang, Rianne de Heide, Émilie Kaufmann, Pierre Ménard, Michal Valko: Fixed-confidence guarantees for Bayesian best-arm identification, in International Conference on Artificial Intelligence and Statistics (AISTATS 2020)
talk
bibtex
arXiv preprint abstract
We investigate and provide new insights on the sampling rule called Top-Two Thompson Sampling (TTTS). In particular, we justify its use for fixed-confidence best-arm identification. We further propose a variant of TTTS called Top-Two Transportation Cost (T3C), which disposes of the computational burden of TTTS. As our main contribution, we provide the first sample complexity analysis of TTTS and T3C when coupled with a very natural Bayesian stopping rule, for bandits with Gaussian rewards, solving one of the open questions raised by Russo (2016). We also provide new posterior convergence results for TTTS under two models that are commonly used in practice: bandits with Gaussian and Bernoulli rewards and conjugate priors.
- Côme Fiegel, Victor Gabillon, Michal Valko: Adaptive multi-fidelity optimization with fast learning rates, in International Conference on Artificial Intelligence and Statistics (AISTATS 2020)
bibtex abstract
In multi-fidelity optimization, biased approximations of varying costs of the target function are available. This paper studies the problem of optimizing a locally smooth function with a limited budget, where the learner has to make a tradeoff between the cost and the bias of these approximations. We first prove lower bounds for the simple regret under different assumptions on the fidelities, based on a cost-to-bias function. We then present the Kometo algorithm which achieves, with additional logarithmic factors, the same rates without any knowledge of the function smoothness and fidelity assumptions, and improves previously proven guarantees. We finally empirically show that our algorithm outperforms previous multi-fidelity optimization methods without the knowledge of problem-dependent parameters.
- Victor Gabillon, Rasul Tutunov, Haitham Bou Ammar, Michal Valko: Derivative-free & order-robust optimisation, in International Conference on Artificial Intelligence and Statistics (AISTATS 2020)
arXiv preprint
bibtex
talk abstract
In this paper, we formalise order-robust optimisation as an instance of online learning minimising simple regret, and propose Vroom, a zero'th order optimisation algorithm capable of achieving vanishing regret in non-stationary environments, while recovering favorable rates under stochastic reward-generating processes. Our results are the first to target simple regret definitions in adversarial scenarios unveiling a challenge that has been rarely considered in prior work.
- Julien Seznec, Pierre Ménard, Alessandro Lazaric, Michal Valko: A single algorithm for both restless and rested rotting bandits, in International Conference on Artificial Intelligence and Statistics (AISTATS 2020)
bibtex
talk abstract
In many application domains (e.g., recommender systems, intelligent tutoring systems), the rewards associated to the available actions tend to decrease over time. This decay is either caused by the actions executed in the past (e.g., a user may get bored when songs of the same genre are recommended over and over) or by an external factor (e.g., content becomes outdated). These two situations can be modeled as specific instances of the rested and restless bandit settings, where arms are rotting (i.e., their value decrease over time). These problems were thought to be significantly different, since Levine et al. (2017) showed that state-of-the-art algorithms for restless bandit perform poorly in the rested rotting setting. In this paper, we introduce a novel algorithm, Rotting Adaptive Window UCB (RAW-UCB), that achieves near-optimal regret in both rotting rested and restless bandit, without any prior knowledge of the setting (rested or restless) and the type of non-stationarity (e.g., piece-wise constant, bounded variation). This is in striking contrast with previous negative results showing that no algorithm can achieve similar results as soon as rewards are allowed to increase. We confirm our theoretical findings on a number of synthetic and dataset-based experiments.
- Jean Tarbouriech, Matteo Pirotta, Michal Valko, Alessandro Lazaric: Reward-free exploration beyond finite-horizon, in Theoretical Foundations of RL Workshop @ ICML 2020 (ICML 2020 - RL Theory)
video
bibtex abstract
We consider the reward-free exploration framework introduced by Jin et al. (2020), where an RL agent interacts with an unknown environment without any explicit reward function to maximize. The objective is to collect enough information during the exploration phase, so that a near-optimal policy can be immediately computed once any reward function is provided. In this paper, we move from the finite-horizon setting studied by Jin et al. (2020) to the more general setting of goal-conditioned RL, often referred to as stochastic shortest path (SSP). We first discuss the challenges specific to SSPs and then study two scenarios: 1) reward-free goal-free exploration in communicating MDPs, and 2) reward-free goal-free incremental exploration in non-communicating MDPs where the agent is provided with a reset action to an initial state. In both cases, we provide exploration algorithms and their sample-complexity bounds which we contrast with the existing guarantees in the finite-horizon case.
- Tomáš Kocák, Rémi Munos, Branislav Kveton, Shipra Agrawal, Michal Valko: Spectral bandits, in Journal of Machine Learning Research (JMLR 2020)
arXiv preprint
bibtex abstract
Smooth functions on graphs have wide applications in manifold and semi-supervised learning. In this work, we study a bandit problem where the payoffs of arms are smooth on a graph. This framework is suitable for solving online learning problems that involve graphs, such as content-based recommendation. In this problem, each item we can recommend is a node of an undirected graph and its expected rating is similar to the one of its neighbors. The goal is to recommend items that have high expected ratings. We aim for the algorithms where the cumulative regret with respect to the optimal policy would not scale poorly with the number of nodes. In particular, we introduce the notion of an effective dimension, which is small in real-world graphs, and propose three algorithms for solving our problem that scale linearly and sublinearly in this dimension. Our experiments on content recommendation problem show that a good estimator of user preferences for thousands of items can be learned from just tens of node evaluations.
{kind=link}
{kind=link}
{kind=link}
2019
- Jean-Bastien Grill*, Omar Darwiche Domingues*, Pierre Ménard, Rémi Munos, Michal Valko: Planning in entropy-regularized Markov decision processes and games, in Neural Information Processing Systems (NeurIPS 2019)
bibtex
poster abstract
We propose SmoothCruiser, a new planning algorithm for estimating the value function in entropy-regularized Markov decision processes and two-player games, given a generative model of the environment. SmoothCruiser makes use of the smoothness of the Bellman operator promoted by the regularization to achieve problem-independent sample complexity of order O(1/epsilon^4) for a desired accuracy epsilon, whereas for non-regularized settings there are no known algorithms with guaranteed polynomial sample complexity in the worst case.
- Mark Rowland, Shayegan Omidshafiei, Karl Tuyls, Julien Pérolat, Michal Valko, Georgios Piliouras, Rémi Munos: Multiagent evaluation under incomplete information, in Neural Information Processing Systems (NeurIPS 2019)
arXiv preprint
bibtex
poster abstract
This paper investigates the evaluation of learned multiagent strategies in the incomplete information setting, which plays a critical role in ranking and training of agents. Traditionally, researchers have relied on Elo ratings for this purpose, with recent works also using methods based on Nash equilibria. Unfortunately, Elo is unable to handle intransitive agent interactions, and other techniques are restricted to zero-sum, two-player settings or are limited by the fact that the Nash equilibrium is intractable to compute. Recently, a ranking method called α-Rank, relying on a new graph-based game-theoretic solution concept, was shown to tractably apply to general games. However, evaluations based on Elo or α-Rank typically assume noise-free game outcomes, despite the data often being collected from noisy simulations, making this assumption unrealistic in practice. This paper investigates multiagent evaluation in the incomplete information regime, involving general-sum many-player games with noisy outcomes. We derive sample complexity guarantees required to confidently rank agents in this setting. We propose adaptive algorithms for accurate ranking, provide correctness and sample complexity guarantees, then introduce a means of connecting uncertainties in noisy match outcomes to uncertainties in rankings. We evaluate the performance of these approaches in several domains, including Bernoulli games, a soccer meta-game, and Kuhn poker.
- Michał Dereziński*, Daniele Calandriello*, Michal Valko: Exact sampling of determinantal point processes with sublinear time preprocessing, in Neural Information Processing Systems (NeurIPS 2019) (ICML 2019 - NEGDEP)
arXiv preprint
bibtex
video abstract
We study the complexity of sampling from a distribution over all index subsets of the set (1,...,n) with the probability of a subset S proportional to the determinant of the submatrix LS of some n x n p.s.d. matrix L, where LS corresponds to the entries of L indexed by S. Known as a determinantal point process, this distribution is used in machine learning to induce diversity in subset selection. In practice, we often wish to sample multiple subsets S with small expected size k = E[card(S)] that are all drawn independently from the same distribution. The standard algorithm for sampling a set uses a spectral decomposition of the matrix L, which requires a full rank update to the matrix for every sample, and thus O(n^3) preprocessing time per sample after the initial eigendecomposition. In this paper, we show that, in certain regimes, it is possible to reduce the preprocessing time to O(n^2 log^2 n) per sample, which is sublinear in the matrix size, while maintaining the exact sampling distribution. We achieve this by using a randomized algorithm that samples from a distribution that is close to the desired distribution in total variation distance, and then show how to correct for the bias efficiently. Our algorithm leverages properties of determinantal point processes and uses a novel approach to approximate the eigendecomposition of the kernel matrix.
- Guillaume Gautier, Rémi Bardenet, Michal Valko: On two ways to use determinantal point processes for Monte Carlo integration, in Neural Information Processing Systems (NeurIPS 2019) (ICML 2019 - NEGDEP)
bibtex
video abstract
When approximating an integral by a weighted sum of function evaluations, determinantal point processes (DPPs) provide a way to enforce repulsion between the evaluation points. We analyze the Ermakov-Zolotukhin estimator using modern arguments and provide an efficient implementation to sample exactly a particular multidimensional DPP called multivariate Jacobi ensemble. We investigate the behavior of two unbiased Monte Carlo estimators and demonstrate good properties when the kernel is adapted to a basis in which the integrand is sparse or has fast-decaying coefficients.
- Daniele Calandriello, Luigi Carratino, Alessandro Lazaric, Michal Valko, Lorenzo Rosasco: Gaussian process optimization with adaptive sketching: Scalable and no regret, in Conference on Learning Theory (COLT 2019) (ICML 2019 - NEGDEP) (SWSL 2019)
arXiv preprint
bibtex
video
talk
poster
poster (image) abstract
Gaussian processes (GP) are a popular Bayesian approach for the optimization of black-box functions. Despite their effectiveness in simple problems, GP-based algorithms hardly scale to complex high-dimensional functions, as their per-iteration time and space cost is at least quadratic in the number of dimensions d and iterations t. Given a set of A alternative to choose from, the overall runtime O(t3A) quickly becomes prohibitive. In this paper, we introduce BKB (budgeted kernelized bandit), a novel approximate GP algorithm for optimization under bandit feedback that achieves near-optimal regret (and hence near-optimal convergence rate) with near-constant per-iteration complexity and no assumption on the input space or covariance of the GP. Combining a kernelized linear bandit algorithm (GP-UCB) with randomized matrix sketching technique (i.e., leverage score sampling), we prove that selecting inducing points based on their posterior variance gives an accurate low-rank approximation of the GP, preserving variance estimates and confidence intervals. As a consequence, BKB does not suffer from variance starvation, an important problem faced by many previous sparse GP approximations. Moreover, we show that our procedure selects at most Õ (deff) points, where deff is the effective dimension of the explored space, which is typically much smaller than both d and t. This greatly reduces the dimensionality of the problem, thus leading to a O(TAd2eff) runtime and O(Adeff) space complexity.
- Peter Bartlett, Victor Gabillon, Jennifer Healey, Michal Valko: Scale-free adaptive planning for deterministic dynamics & discounted rewards, in International Conference on Machine Learning (ICML 2019)
bibtex
video
talk
poster abstract
We address the problem of planning in an environment with deterministic dynamics and stochastic discounted rewards under a limited numerical budget where the ranges of both rewards and noise are unknown. We introduce PlaTypOOS, an adaptive, robust, and efficient alternative to the OLOP (open-loop optimistic planning) algorithm. Whereas OLOP requires a priori knowledge of the ranges of both rewards and noise, PlaTypOOS dynamically adapts its behavior to both. This allows PlaTypOOS to be immune to two vulnerabilities of OLOP: failure when given underestimated ranges of noise and rewards and inefficiency when these are overestimated. PlaTypOOS additionally adapts to the global smoothness of the value function. PlaTypOOS acts in a provably more efficient manner vs. OLOP when OLOP is given an overestimated reward and show that in the case of no noise, PlaTypOOS learns exponentially faster.
- Pierre Perrault, Vianney Perchet, Michal Valko: Exploiting structure of uncertainty for efficient matroid semi-bandits, in International Conference on Machine Learning (ICML 2019)
arXiv preprint
bibtex
video
talk
poster
poster (image) abstract
We improve the efficiency of algorithms for stochastic combinatorial semi-bandits. In most interesting problems, state-of-the-art algorithms take advantage of structural properties of rewards, such as independence. However, while being minimax optimal in terms of regret, these algorithms are intractable. In our paper, we first reduce their implementation to a specific submodular maximization. Then, in case of matroid constraints, we design adapted approximation routines, thereby providing the first efficient algorithms that exploit the reward structure. In particular, we improve the state-of-the-art efficient gap-free regret bound by a factor sqrt(k), where k is the maximum action size. Finally, we show how our improvement translates to more general budgeted combinatorial semi-bandits.
- Xuedong Shang, Émilie Kaufmann, Michal Valko: A simple dynamic bandit-based algorithm for hyper-parameter tuning, in Workshop on Automated Machine Learning at International Conference on Machine Learning (ICML 2019 - AutoML)
bibtex
poster
code abstract
Hyper-parameter tuning is a major part of modern machine learning systems. The tuning itself can be seen as a sequential resource allocation problem. As such, methods for multi-armed bandits have been already applied. In this paper, we view hyper-parameter optimization as an instance of best-arm identification in infinitely many-armed bandits. We propose D-TTTS, a new adaptive algorithm inspired by Thompson sampling, which dynamically balances between refining the estimate of the quality of hyper-parameter configurations previously explored and adding new hyper-parameter configurations to the pool of candidates. The algorithm is easy to implement and shows competitive performance compared to state-of-the-art algorithms for hyper-parameter tuning.
- Guillaume Gautier, Guillermo Polito, Rémi Bardenet, Michal Valko: DPPy: Sampling determinantal point processes with Python, in Journal of Machine Learning Research (JMLR 2019)
arXiv preprint
bibtex abstract
Determinantal point processes (DPPs) are specific probability distributions over clouds of points that are used as models and computational tools across physics, probability, statistics, and more recently machine learning. Sampling from DPPs is a challenge and therefore we present DPPy, a Python toolbox that gathers known exact and approximate sampling algorithms. The project is hosted on GitHub and equipped with an extensive documentation. This documentation takes the form of a short survey of DPPs and relates each mathematical property with DPPy objects.
- Julien Seznec, Andrea Locatelli, Alexandra Carpentier, Alessandro Lazaric, Michal Valko: Rotting bandits are not harder than stochastic ones, in International Conference on Artificial Intelligence and Statistics (AISTATS 2019) [full oral presentation - 2.5% acceptance rate]
arXiv preprint
bibtex
talk
poster abstract
In stochastic multi-armed bandits, the reward distribution of each arm is assumed to be stationary. This assumption is often violated in practice (e.g., in recommendation systems), where the reward of an arm may change whenever is selected, i.e., rested bandit setting. In this paper, we consider the non-parametric rotting bandit setting, where rewards can only decrease. We introduce the filtering on expanding window average (FEWA) algorithm that constructs moving averages of increasing windows to identify arms that are more likely to return high rewards when pulled once more. We prove that for an unknown horizon T, and without any knowledge on the decreasing behavior of the K arms, FEWA achieves problem-dependent regret bound of O(log(KT)), and a problem-independent one of O(sqrt(KT)). Our result substantially improves over the algorithm of Levine et al. (2017), which suffers regret ˜(K1/3T2/3). FEWA also matches known bounds for the stochastic bandit setting, thus showing that the rotting bandits are not harder. Finally, we report simulations confirming the theoretical improvements of FEWA.
- Andrea Locatelli, Alexandra Carpentier, Michal Valko: Active multiple matrix completion with adaptive confidence sets, in International Conference on Artificial Intelligence and Statistics (AISTATS 2019)
bibtex
talk
poster abstract
In this work, we formulate a new multi-task active learning setting in which the learner's goal is to solve multiple matrix completion problems simultaneously. At each round, the learner can choose from which matrix it receives a sample from an entry drawn uniformly at random. Our main practical motivation is market segmentation, where the matrices represent different regions with different preferences of the customers. The challenge in this setting is that each of the matrices can be of a different size and also of a different rank which is unknown. We provide and analyze a new algorithm, MAlocate that is able to adapt to the unknown ranks of the different matrices. We then give a lower-bound showing that our strategy is minimax-optimal and demonstrate its performance with synthetic experiments.
- Pierre Perrault, Vianney Perchet, Michal Valko: Finding the bandit in a graph: Sequential search-and-stop, in International Conference on Artificial Intelligence and Statistics (AISTATS 2019)
arXiv preprint
bibtex
poster abstract
We consider the problem where an agent wants to find a hidden object that is randomly located in some vertex of a directed acyclic graph (DAG) according to a fixed but possibly unknown distribution. The agent can only examine vertices whose in-neighbors have already been examined. In scheduling theory, this problem is denoted by 1|prec|∑wjCj [Graham1979]. However, in this paper we address a learning setting where we allow the agent to stop before having found the object and restart searching on a new independent instance of the same problem. The goal is to maximize the total number of hidden objects found under a time constraint. The agent can thus skip an instance after realizing that it would spend too much time on it. Our contributions are both to the search theory and multi-armed bandits. If the distribution is known, we provide a quasi-optimal greedy strategy with the help of known computationally efficient algorithms for solving 1|prec|∑wjCj under some assumption on the DAG. If the distribution is unknown, we show how to sequentially learn it and, at the same time, act near-optimally in order to collect as many hidden objects as possible. We provide an algorithm, prove theoretical guarantees, and empirically show that it outperforms the naive baseline.
- Peter L. Bartlett, Victor Gabillon, Michal Valko: A simple parameter-free and adaptive approach to optimization under a minimal local smoothness assumption, in Algorithmic Learning Theory (ALT 2019)
arXiv preprint
bibtex
talk 1
talk 2 abstract
We study the problem of optimizing a function under a budgeted number of evaluations. We only assume that the function is locally smooth around one of its global optima. The difficulty of optimization is measured in terms of 1) the amount of noise b of the function evaluation and 2) the local smoothness, d, of the function. A smaller d results in smaller optimization error. We come with a new, simple, and parameter-free approach. First, for all values of b and d, this approach recovers at least the state-of-the-art regret guarantees. Second, our approach additionally obtains these results while being agnostic to the values of both b and d. This leads to the first algorithm that naturally adapts to an unknown range of noise b and leads to significant improvements in a moderate and low-noise regime. Third, our approach also obtains a remarkable improvement over the state-of-the-art SOO algorithm when the noise is very low which includes the case of optimization under deterministic feedback (b=0). There, under our minimal local smoothness assumption, this improvement is of exponential magnitude and holds for a class of functions that covers the vast majority of functions that practitioners optimize (d=0). We show that our algorithmic improvement is borne out in experiments as we empirically show faster convergence on common benchmarks.
- Xuedong Shang, Émilie Kaufmann, Michal Valko: General parallel optimization without metric, in Algorithmic Learning Theory (ALT 2019)
bibtex
talk abstract
Hierarchical bandits are an approach for global optimization of extremely irregular functions. This paper provides new elements regarding POO, an adaptive meta-algorithm that does not require the knowledge of local smoothness of the target function. We first highlight the fact that the subroutine algorithm used in POO should have a small regret under the assumption of local smoothness with respect to the chosen partitioning, which is unknown if it is satisfied by the standard subroutine HOO. In this work, we establish such regret guarantee for HCT, which is another hierarchical optimistic optimization algorithm that needs to know the smoothness. This confirms the validity of POO. We show that POO can be used with HCT as a subroutine with a regret upper bound that matches the one of best-known algorithms using the knowledge of smoothness up to a √ log n factor. On top of that, we propose a general wrapper, called GPO, that can cope with algorithms that only have simple regret guarantees. Finally, we complement our findings with experiments on difficult functions.
- Guillaume Gautier, Rémi Bardenet, Michal Valko: Les processus ponctuels déterminantaux en apprentissage automatique, (Gretsi 2019)
bibtex abstract
For the session ``Mathematical tools in machine learning", we propose a short survey of determinantal point processes, a popular probabilistic model and tool in machine learning, which already has promising applications in signal processing.
- Fabrice Popineau, Michal Valko, Jill-Jênn Vie: Optimizing human learning workshop eliciting adaptive sequences for learning (WeASeL), in CEUR Workshop Proceedings (CEUR 2019)
bibtex abstract
Proceedings of the Workshop on Optimizing Human Learning, eliciting Adaptive Sequences for Learning (WeASeL), held in conjunction with ITS 2019. The workshop focused on the intersection of machine learning and human learning, exploring how adaptive sequencing algorithms can optimize educational content delivery.
{kind=link}
{kind=link}
2018
- Jean-Bastien Grill, Michal Valko, Rémi Munos: Optimistic optimization of a Brownian, in Neural Information Processing Systems (NeurIPS 2018)
arXiv preprint
bibtex
poster abstract
We address the problem of optimizing a Brownian motion. We consider a (random) realization W of a Brownian motion with input space in [0,1]. Given W, our goal is to return an epsilon-approximation of its maximum using the smallest possible number of function evaluations, the sample complexity of the algorithm. We provide an algorithm with sample complexity of order log2(1/epsilon). This improves over previous results of Al-Mharmah and Calvin (1996) and Calvin et al. (2017) which provided only polynomial rates. Our algorithm is adaptive---each query depends on previous values---and is an instance of the optimism-in-the-face-of-uncertainty principle.
- Xuedong Shang, Émilie Kaufmann, Michal Valko: Adaptive black-box optimization got easier: HCT needs only local smoothness, in European Workshop on Reinforcement Learning (EWRL 2018)
bibtex
poster abstract
Hierarchical bandits is an approach for global optimization of extremely irregular functions. This paper provides new elements regarding POO, an adaptive meta-algorithm that does not require the knowledge of local smoothness of the target function. We first highlight the fact that the sub-routine algorithm used in POO should have a small regret under the assumption of local smoothness with respect to the chosen partitioning, which is unknown if it is satisfied by the standard sub-routine HOO. In this work, we establish such regret guarantee for HCT which is another hierarchical optimistic optimization algorithm that needs to know the smoothness. This confirms the validity of POO. We show that POO can be used with HCT as a sub-routine with a regret upper bound that matches that of best-known algorithms using the knowledge of smoothness up to a sqrt(log(n)) factor.
- Édouard Oyallon, Eugene Belilovsky, Sergey Zagoruyko, Michal Valko: Compressing the input for CNNs with the first-order scattering transform, in European Conference on Computer Vision (ECCV 2018)
arXiv preprint
bibtex
poster abstract
We study the first-order scattering transform as a candidate for reducing the signal processed by a convolutional neural network (CNN). We show theoretical and empirical evidence that in the case of natural images and sufficiently small translation invariance, this transform preserves most of the signal information needed for classification while substantially reducing the spatial resolution and total signal size. We demonstrate that cascading a CNN with this representation performs on par with ImageNet classification models, commonly used in downstream tasks, such as the ResNet-50. We subsequently apply our trained hybrid ImageNet model as a base model on a detection system, which has typically larger image inputs. On Pascal VOC and COCO detection tasks we demonstrate improvements in the inference speed and training memory consumption compared to models trained directly on the input image.
- Daniele Calandriello, Ioannis Koutis, Alessandro Lazaric, Michal Valko: Improved large-scale graph learning through ridge spectral sparsification, in International Conference on Machine Learning (ICML 2018)
bibtex
talk
poster abstract
The representation and learning benefits of methods based on graph Laplacians, such as Laplacian smoothing or harmonic function solution for semi-supervised learning (SSL), are empirically and theoretically well supported. Nonetheless, the exact versions of these methods scale poorly with the number of nodes n of the graph. In this paper, we combine a spectral sparsification routine with Laplacian learning. Given a graph G as input, our algorithm computes a sparsifier in a distributed way in O(nlog3(n)) time, O(mlog3(n)) work and O(nlog(n)) memory, using only log(n) rounds of communication. Furthermore, motivated by the regularization often employed in learning algorithms, we show that constructing sparsifiers that preserve the spectrum of the Laplacian only up to the regularization level may drastically reduce the size of the final graph. By constructing a spectrally-similar graph, we are able to bound the error induced by the sparsification for a variety of downstream tasks (e.g., SSL). We empirically validate the theoretical guarantees on Amazon co-purchase graph and compare to the state-of-the-art heuristics.
- Yasin Abbasi-Yadkori, Peter L. Bartlett, Victor Gabillon, Alan Malek, Michal Valko: Best of both worlds: Stochastic & adversarial best-arm identification, (COLT 2018)
bibtex
video
talk
poster abstract
We study bandit best-arm identification with arbitrary and potentially adversarial rewards. A simple random uniform learner obtains the optimal rate of error in the adversarial scenario. However, this type of strategy is suboptimal when the rewards are sampled stochastically. Therefore, we ask: Can we design a learner that performs optimally in both the stochastic and adversarial problems while not being aware of the nature of the rewards? First, we show that designing such a learner is impossible in general. In particular, to be robust to adversarial rewards, we can only guarantee optimal rates of error on a subset of the stochastic problems. We give a lower bound that characterizes the optimal rate in stochastic problems if the strategy is constrained to be robust to adversarial rewards. Finally, we design a simple parameter-free algorithm and show that its probability of error matches (up to log factors) the lower bound in stochastic problems, and it is also robust to adversarial ones.
2017
- Daniele Calandriello, Alessandro Lazaric, Michal Valko: Efficient second-order online kernel learning with adaptive embedding, in Neural Information Processing Systems (NeurIPS 2017)
bibtex
talk
poster abstract
Online kernel learning (OKL) is a flexible framework to approach prediction problems, since the large approximation space provided by reproducing kernel Hilbert spaces can contain an accurate function for the problem. Nonetheless, optimizing over this space is computationally expensive. Not only first order methods accumulate O( sqrt T ) more loss than the optimal function, but the curse of kernelization results in a O(t) per step complexity. Second-order methods get closer to the optimum much faster, suffering only O( log(T)) regret, but second-order updates are even more expensive, with a O(t 2) per-step cost. Existing approximate OKL methods try to reduce this complexity either by limiting the Support Vectors (SV) introduced in the predictor, or by avoiding the kernelization process altogether using embedding. Nonetheless, as long as the size of the approximation space or the number of SV does not grow over time, an adversary can always exploit the approximation process. In this paper, we propose PROS-N-KONS, a method that combines Nystrom sketching to project the input point in a small, accurate embedded space, and performs efficient second-order updates in this space. The embedded space is continuously updated to guarantee that the embedding remains accurate, and we show that the per-step cost only grows with the effective dimension of the problem and not with T . Moreover, the second-order updated allows us to achieve the logarithmic regret. We empirically compare our algorithm on recent large-scales benchmarks and show it performs favorably.
- Zheng Wen, Branislav Kveton, Michal Valko, Sharan Vaswani: Online influence maximization under independent cascade model with semi-bandit feedback, in Neural Information Processing Systems (NeurIPS 2017)
arXiv preprint
bibtex abstract
We study the online influence maximization problem in social networks under the independent cascade model. Specifically, we aim to learn the set of " best influencers " in a social network online while repeatedly interacting with it. We address the challenges of (i) combinatorial action space, since the number of feasible influencer sets grows exponentially with the maximum number of influencers, and (ii) limited feedback, since only the influenced portion of the network is observed. Under a stochastic semi-bandit feedback, we propose and analyze IMLinUCB, a computationally efficient UCB-based algorithm. Our bounds on the cumulative regret are polynomial in all quantities of interest, achieve near-optimal dependence on the number of interactions and reflect the topology of the network and the activation probabilities of its edges, thereby giving insights on the problem complexity. To the best of our knowledge, these are the first such results. Our experiments show that in several representative graph topologies, the regret of IMLinUCB scales as suggested by our upper bounds. IMLinUCB permits linear generalization and thus is both statistically and computationally suitable for large-scale problems. Our experiments also show that IMLinUCB with linear generalization can lead to low regret in real-world online influence maximization.
- Daniele Calandriello, Alessandro Lazaric, Michal Valko: Second-order kernel online convex optimization with adaptive sketching, in International Conference on Machine Learning (ICML 2017)
arXiv preprint
bibtex
talk
poster abstract
Kernel online convex optimization (KOCO) is a framework combining the expressiveness of non-parametric kernel models with the regret guarantees of online learning. First-order KOCO methods such as functional gradient descent require only O(t) time and space per iteration, and, when the only information on the losses is their convexity, achieve a minimax optimal O(sqrtT) regret. Nonetheless, many common losses in kernel problems, such as squared loss, logistic loss, and squared hinge loss posses stronger curvature that can be exploited. In this case, second-order KOCO methods achieve O(log(Det(K))) regret, which we show scales as O(deff log T), where deff is the effective dimension of the problem and is usually much smaller than O(sqrtT). The main drawback of second-order methods is their much higher O(t 2) space and time complexity. In this paper, we introduce kernel online Newton step (KONS), a new second-order KOCO method that also achieves O(defflog T) regret. To address the computational complexity of second-order methods, we introduce a new matrix sketching algorithm for the kernel matrix K, and show that for a chosen parameter gamma leq 1 our Sketched-KONS reduces the space and time complexity by a factor of gamma 2 to O(t 2gamma 2) space and time per iteration, while incurring only 1/gamma times more regret.
- Guillaume Gautier, Rémi Bardenet, Michal Valko: Zonotope hit-and-run for efficient sampling from projection DPPs, in International Conference on Machine Learning (ICML 2017)
arXiv preprint
bibtex
talk
poster abstract
Determinantal point processes (DPPs) are distributions over sets of items that model diversity using kernels. Their applications in machine learning include summary extraction and recommendation systems. Yet, the cost of sampling from a DPP is prohibitive in large-scale applications, which has triggered an effort towards efficient approximate samplers. We build a novel MCMC sampler that combines ideas from combinatorial geometry, linear programming, and Monte Carlo methods to sample from DPPs with a fixed sample cardinality, also called projection DPPs. Our sampler leverages the ability of the hit-and-run MCMC kernel to efficiently move across convex bodies. Previous theoretical results yield a fast mixing time of our chain when targeting a distribution that is close to a projection DPP, but not a DPP in general. Our empirical results demonstrate that this extends to sampling projection DPPs, i.e., our sampler is more sample-efficient than previous approaches which in turn translates to faster convergence when dealing with costly-to-evaluate functions, such as summary extraction in our experiments.
- Daniele Calandriello, Alessandro Lazaric, Michal Valko: Distributed adaptive sampling for kernel matrix approximation, in International Conference on Artificial Intelligence and Statistics (AISTATS 2017)
LL
arXiv preprint
bibtex
talk
code
poster abstract
Most kernel-based methods, such as kernel regression, kernel PCA, ICA, or k-means clustering, do not scale to large datasets, because constructing and storing the kernel matrix Kn requires at least O(n2) time and space for n samples. Recent works (Alaoui 2014, Musco 2016) show that sampling points with replacement according to their ridge leverage scores (RLS) generates small dictionaries of relevant points with strong spectral approximation guarantees for Kn. The drawback of RLS-based methods is that computing exact RLS requires constructing and storing the whole kernel matrix. In this paper, we introduce SQUEAK, a new algorithm for kernel approximation based on RLS sampling that sequentially processes the dataset, storing a dictionary which creates accurate kernel matrix approximations with a number of points that only depends on the effective dimension deffgamma of the dataset. Moreover since all the RLS estimations are efficiently performed using only the small dictionary, SQUEAK never constructs the whole matrix kermatrixn, runs in linear time widetildeO(ndeffgamma3) w.r.t.n, and requires only a single pass over the dataset. We also propose a parallel and distributed version of SQUEAK achieving similar accuracy in as little as widetildeO(log(n)deffgamma3) time.
- Akram Erraqabi, Alessandro Lazaric, Michal Valko, Emma Brunskill, Yu-En Liu: Trading off rewards and errors in multi-armed bandits, in International Conference on Artificial Intelligence and Statistics (AISTATS 2017)
bibtex
poster abstract
In multi-armed bandits, the most common objective is the maximization of the cumulative reward. Alternative settings include active exploration, where a learner tries to gain accurate estimates of the rewards of all arms. While these objectives are contrasting, in many scenarios it is desirable to trade off rewards and errors. For instance, in educational games the designer wants to gather generalizable knowledge about the behavior of the students and teaching strategies (small estimation errors) but, at the same time, the system needs to avoid giving a bad experience to the players, who may leave the system permanently (large reward). In this paper, we formalize this tradeoff and introduce the ForcingBalance algorithm whose performance is provably close to the best possible tradeoff strategy. Finally, we demonstrate on real-world educational data that ForcingBalance returns useful information about the arms without compromising the overall reward.
2016
- Michal Valko: Bandits on graphs and structures, habilitation thesis, École normale supérieure de Cachan (ENS Cachan 2016)
bibtex
talk abstract
We investigate the structural properties of certain sequential decision-making problems with limited feedback (bandits) in order to bring the known algorithmic solutions closer to a practical use. In the first part, we put a special emphasis on structures that can be represented as graphs on actions, in the second part we study the large action spaces that can be of exponential size in the number of base actions or even infinite. We show how to take advantage of structures over the actions and (provably) learn faster.
- Jean-Bastien Grill, Michal Valko, Rémi Munos: Blazing the trails before beating the path: Sample-efficient Monte-Carlo planning, in Neural Information Processing Systems (NeurIPS 2016) [nominated for the best student paper award, full oral presentation - 1.8% acceptance rate]
bibtex
talk
poster abstract
You are a robot and you live in a Markov decision process (MDP) with a finite or an infinite number of transitions from state-action to next states. You got brains and so you plan before you act. Luckily, your roboparents equipped you with a generative model to do some Monte-Carlo planning. The world is waiting for you and you have no time to waste. You want your planning to be efficient. Sample-efficient. Indeed, you want to exploit the possible structure of the MDP by exploring only a subset of states reachable by following near-optimal policies. You want guarantees on sample complexity that depend on a measure of the quantity of near-optimal states. You want something, that is an extension of Monte-Carlo sampling (for estimating an expectation) to problems that alternate maximization (over actions) and expectation (over next states). But you do not want to StOP with exponential running time, you want something simple to implement and computationally efficient. You want it all and you want it now. You want TrailBlazer.
- Daniele Calandriello, Alessandro Lazaric, Michal Valko: Pack only the essentials: Adaptive dictionary learning for kernel ridge regression, in Adaptive and Scalable Nonparametric Methods in Machine Learning at Neural Information Processing Systems (NeurIPS 2016 - ASNMML)
bibtex
poster abstract
Most kernel-based methods, such as kernel regression, kernel PCA, ICA, or k-means clustering, do not scale to large datasets, because constructing and storing the kernel matrix Kn requires at least O(n2) time and space for n samples. Recent works (Alaoui 2014, Musco 2016) show that sampling points with replacement according to their ridge leverage scores (RLS) generates small dictionaries of relevant points with strong spectral approximation guarantees for Kn. The drawback of RLS-based methods is that computing exact RLS requires constructing and storing the whole kernel matrix. In this paper, we introduce SQUEAK, a new algorithm for kernel approximation based on RLS sampling that sequentially processes the dataset, storing a dictionary which creates accurate kernel matrix approximations with a number of points that only depends on the effective dimension deffgamma of the dataset. Moreover since all the RLS estimations are efficiently performed using only the small dictionary, SQUEAK never constructs the whole matrix kermatrixn, runs in linear time widetildeO(ndeffgamma3) w.r.t.n, and requires only a single pass over the dataset.
- Akram Erraqabi, Alessandro Lazaric, Michal Valko, Emma Brunskill, Yu-En Liu: Rewards and errors in multi-armed bandit for interactive education, in Challenges in Machine Learning: Learning and Education workshop at Neural Information Processing Systems (NeurIPS 2016 - CIML)
bibtex
poster abstract
In multi-armed bandits, the most common objective is the maximization of the cumulative reward. Alternative settings include active exploration, where a learner tries to gain accurate estimates of the rewards of all arms. While these objectives are contrasting, in many scenarios it is desirable to trade off rewards and errors. For instance, in educational games the designer wants to gather generalizable knowledge about the behavior of the students and teaching strategies (small estimation errors) but, at the same time, the system needs to avoid giving a bad experience to the players, who may leave the system permanently (large reward). In this paper, we formalize this tradeoff and introduce the ForcingBalance algorithm whose performance is provably close to the best possible tradeoff strategy. Finally, we demonstrate on real-world educational data that ForcingBalance returns useful information about the arms without compromising the overall reward.
- Akram Erraqabi, Michal Valko, Alexandra Carpentier, Odalric-Ambrym Maillard: Pliable rejection sampling, in International Conference on Machine Learning (ICML 2016)
bibtex
talk
long talk
poster
code abstract
Rejection sampling is a technique for sampling from difficult distributions. However, its use is limited due to a high rejection rate. Common adaptive rejection sampling methods either work only for very specific distributions or without performance guarantees. In this paper, we present pliable rejection sampling (PRS), a new approach to rejection sampling, where we learn the sampling proposal using a kernel estimator. Since our method builds on rejection sampling, the samples obtained are with high probability i.i.d. and distributed according to f. Moreover, PRS comes with a guarantee on the number of accepted samples.
- Daniele Calandriello, Alessandro Lazaric, Michal Valko: Analysis of Nyström method with sequential ridge leverage scores, in Uncertainty in Artificial Intelligence (UAI 2016)
bibtex
poster
spotlight abstract
Large-scale kernel ridge regression (KRR) is limited by the need to store a large kernel matrix Kt. To avoid storing the entire matrix Kt, Nyström methods subsample a subset of columns of the kernel matrix, and efficiently find an approximate KRR solution on the reconstructed Kt . The chosen subsampling distribution in turn affects the statistical and computational tradeoffs. For KRR problems, [15, 1] show that a sampling distribution proportional to the ridge leverage scores (RLSs) provides strong reconstruction guarantees for Kt. While exact RLSs are as difficult to compute as a KRR solution, we may be able to approximate them well enough. In this paper, we study KRR problems in a sequential setting and introduce the INK-ESTIMATE algorithm, that incrementally computes the RLSs estimates. INK-ESTIMATE maintains a small sketch of Kt, that at each step is used to compute an intermediate es- timate of the RLSs. First, our sketch update does not require access to previously seen columns, and therefore a single pass over the kernel ma- trix is sufficient. Second, the algorithm requires a fixed, small space budget to run dependent only on the effective dimension of the kernel matrix. Finally, our sketch provides strong approximation guarantees on the distance ∥Kt−Kt∥2 , and on the statistical risk of the approximate KRR solution at any time, because all our guarantees hold at any intermediate step.
- Tomáš Kocák, Gergely Neu, Michal Valko: Online learning with Erdős-Rényi side-observation graphs, in Uncertainty in Artificial Intelligence (UAI 2016)
arXiv preprint
bibtex
poster
spotlight abstract
We consider adversarial multi-armed bandit problems where the learner is allowed to observe losses of a number of arms beside the arm that it actually chose. We study the case where all non-chosen arms reveal their loss with an unknown probability rt, independently of each other and the action of the learner. Moreover, we allow rt to change in every round t, which rules out the possibility of estimating rt by a well-concentrated sample average. We propose an algorithm which operates under the assumption that rt is large enough to warrant at least one side observation with high probability. We show that after T rounds in a bandit problem with N arms, the expected regret of our algorithm is of order O(sqrt(sum(t=1)T (1/rt) log N )), given that rt less than log T / (2N-2) for all t. All our bounds are within logarithmic factors of the best achievable performance of any algorithm that is even allowed to know exact values of rt.
- Mohammad Ghavamzadeh, Yaakov Engel, Michal Valko: Bayesian policy gradient and actor-critic algorithms, in Journal of Machine Learning Research (JMLR 2016)
arXiv preprint
bibtex
code
code (MATLAB) abstract
Policy gradient methods are reinforcement learning algorithms that adapt a parameterized policy by following a performance gradient estimate. Many conventional policy gradient methods use Monte-Carlo techniques to estimate this gradient. The policy is improved by adjusting the parameters in the direction of the gradient estimate. Since Monte-Carlo methods tend to have high variance, a large number of samples is required to attain accurate estimates, resulting in slow convergence. In this paper, we first propose a Bayesian framework for policy gradient, based on modeling the policy gradient as a Gaussian process. This reduces the number of samples needed to obtain accurate gradient estimates. Moreover, estimates of the natural gradient as well as a measure of the uncertainty in the gradient estimates, namely, the gradient covariance, are provided at little extra cost. Since the proposed Bayesian framework considers system trajectories as its basic observable unit, it does not require the dynamics within trajectories to be of any particular form, and thus, can be easily extended to partially observable problems. On the downside, it cannot take advantage of the Markov property when the system is Markovian. To address this issue, we proceed to supplement our Bayesian policy gradient framework with a new actor-critic learning model in which a Bayesian class of non- parametric critics, based on Gaussian process temporal difference learning, is used. Such critics model the action- value function as a Gaussian process, allowing Bayes' rule to be used in computing the posterior distribution over action-value functions, conditioned on the observed data. Appropriate choices of the policy parameterization and of the prior covariance (kernel) between action-values allow us to obtain closed-form expressions for the posterior distribution of the gradient of the expected return with respect to the policy parameters. We perform detailed experimental comparisons of the proposed Bayesian policy gradient and actor-critic algorithms with classic Monte-Carlo based policy gradient methods, as well as with each other, on a number of reinforcement learning problems.
- Tomáš Kocák, Gergely Neu, Michal Valko: Online learning with noisy side observations, in International Conference on Artificial Intelligence and Statistics (AISTATS 2016) [full oral presentation - 6% acceptance rate]
arXiv preprint
bibtex
talk
poster abstract
We propose a new partial-observability model for online learning problems where the learner, besides its own loss, also observes some noisy feedback about the other actions, depending on the underlying structure of the problem. We represent this structure by a weighted directed graph, where the edge weights are related to the quality of the feedback shared by the connected nodes. Our main contribution is an efficient algorithm that guarantees a regret of O(sqrt(alpha* T)) after T rounds, where alpha* is a novel graph property that we call the effective independence number. Our algorithm is completely parameter-free and does not require knowledge (or even estimation) of alpha*. For the special case of binary edge weights, our setting reduces to the partial-observability models of Mannor & Shamir (2011) and Alon et al. (2013) and our algorithm recovers the near-optimal regret bounds.
- Alexandra Carpentier, Michal Valko: Revealing graph bandits for maximizing local influence, in International Conference on Artificial Intelligence and Statistics (AISTATS 2016)
bibtex
poster abstract
We study a graph bandit setting where the objective of the learner is to detect the most influential node of a graph by requesting as little information from the graph as possible. One of the relevant applications for this setting is marketing in social networks, where the marketer aims at finding and taking advantage of the most influential customers. The existing approaches for bandit problems on graphs require either partial or complete knowledge of the graph. In this paper, we do not assume any knowledge of the graph, but we consider a setting where it can be gradually discovered in a sequential and active way. At each round, the learner chooses a node of the graph and the only information it receives is a stochastic set of the nodes that the chosen node is currently influencing. To address this setting, we propose BARE, a bandit strategy for which we prove a regret guarantee that scales with the detectable dimension, a problem dependent quantity that is often much smaller than the number of nodes.
- Daniele Calandriello, Alessandro Lazaric, Michal Valko: Analysis of Kelner and Levin graph sparsification algorithm for a streaming setting, (arXiv 2016)
arXiv preprint
bibtex abstract
We present an improved proof that the incremental resparsification algorithm from Kelner and Levin (2013) generates a spectral sparsifier with high probability. Our key contribution involves rigorously handling dependencies between consecutive resparsifications through martingale inequalities, thereby addressing a gap in the original analysis.
- Daniele Calandriello, Alessandro Lazaric, Michal Valko, Ioannis Koutis: Incremental spectral sparsification for large-scale graph-based semi-supervised learning, (arXiv 2016)
arXiv preprint abstract
While the harmonic function solution performs well in many semi-supervised learning (SSL) tasks, it is known to scale poorly with the number of samples. Recent successful and scalable methods, such as the eigenfunction method focus on efficiently approximating the whole spectrum of the graph Laplacian constructed from the data. This is in contrast to various subsampling and quantization methods proposed in the past, which may fail in preserving the graph spectra. However, the impact of the approximation of the spectrum on the final generalization error is either unknown, or requires strong assumptions on the data. In this paper, we introduce Sparse-HFS, an efficient edge-sparsification algorithm for SSL. By constructing an edge-sparse and spectrally similar graph, we are able to leverage the approximation guarantees of spectral sparsification methods to bound the generalization error of Sparse-HFS. As a result, we obtain a theoretically-grounded approximation scheme for graph-based SSL that also empirically matches the performance of known large-scale methods.
2015
- Jean-Bastien Grill, Michal Valko, Rémi Munos: Black-box optimization of noisy functions with unknown smoothness, in Neural Information Processing Systems (NeurIPS 2015)
bibtex
code
code in R
poster abstract
We study the problem of black-box optimization of a function f of any dimension, given function evaluations perturbed by noise. The function is assumed to be locally smooth around one of its global optima, but this smoothness is unknown. Our contribution is an adaptive optimization algorithm, POO or parallel optimistic optimization, that is able to deal with this setting. POO performs almost as well as the best known algorithms requiring the knowledge of the smoothness. Furthermore, POO works for a larger class of functions than what was previously considered, especially for functions that are difficult to optimize, in a very precise sense. We provide a finite-time analysis of POO's performance, which shows that its error after n evaluations is at most a factor of sqrt(ln n) away from the error of the best known optimization algorithms using the knowledge of the smoothness.
- Alexandra Carpentier, Michal Valko: Simple regret for infinitely many armed bandits, in International Conference on Machine Learning (ICML 2015)
bibtex
talk
poster
arXiv abstract
We consider a stochastic bandit problem with infinitely many arms. In this setting, the learner has no chance of trying all the arms even once and has to dedicate its limited number of samples only to a certain number of arms. All previous algorithms for this setting were designed for minimizing the cumulative regret of the learner. In this paper, we propose an algorithm aiming at minimizing the simple regret. As in the cumulative regret setting of infinitely many armed bandits, the rate of the simple regret will depend on a parameter \$\backslash beta\$ characterizing the distribution of the near-optimal arms. We prove that depending on \$\backslash beta\$, our algorithm is minimax optimal either up to a multiplicative constant or up to a \$\backslash log(n)\$ factor. We also provide extensions to several important cases: when \$\backslash beta\$ is unknown, in a natural setting where the near-optimal arms have a small variance, and in the case of unknown time horizon.
- Manjesh Hanawal, Venkatesh Saligrama, Michal Valko, Rémi Munos: Cheap bandits, in International Conference on Machine Learning (ICML 2015)
arXiv preprint
bibtex
talk
poster abstract
We consider stochastic sequential learning problems where the learner can observe the average reward of several actions. Such a setting is interesting in many applications involving monitoring and surveillance, where the set of the actions to observe represent some (geographical) area. The importance of this setting is that in these applications, it is actually cheaper to observe average reward of a group of actions rather than the reward of a single action. We show that when the reward is smooth over a given graph representing the neighboring actions, we can maximize the cumulative reward of learning while minimizing the sensing cost. In this paper we propose CheapUCB, an algorithm that matches the regret guarantees of the known algorithms for this setting and at the same time guarantees a linear cost again over them. As a by-product of our analysis, we establish a Omega($\backslash$sqrt(dT)) lower bound on the cumulative regret of spectral bandits for a class of graphs with effective dimension d.
- Daniele Calandriello, Alessandro Lazaric, Michal Valko: Large-scale semi-supervised learning with online spectral graph sparsification, in Resource-Efficient Machine Learning workshop at International Conference on Machine Learning (ICML 2015 - REML)
arXiv preprint
bibtex
poster abstract
We introduce Sparse-HFS, a scalable algorithm that can compute solutions to SSL problems using only O(n polylog(n)) space and O(m polylog(n)) time.
- Julien Audiffren, Michal Valko, Alessandro Lazaric, Mohammad Ghavamzadeh: Maximum entropy semi-supervised inverse reinforcement learning, in International Joint Conference on Artificial Intelligence (IJCAI 2015) (NeurIPS 2014 - TCRL)
NIPS Workshop on Novel Trends and Applications in Reinforcement Learning
bibtex
talk
poster abstract
A popular approach to apprenticeship learning (AL) is to formulate it as an inverse reinforcement learning (IRL) problem. The MaxEnt-IRL algorithm successfully integrates the maximum entropy principle into IRL and unlike its predecessors, it resolves the ambiguity arising from the fact that a possibly large number of policies could match the expert's behavior. In this paper, we study an AL setting in which in addition to the expert's trajectories, a number of unsupervised trajectories is available. We introduce MESSI, a novel algorithm that combines MaxEnt-IRL with principles coming from semi-supervised learning. In particular, MESSI integrates the unsupervised data into the MaxEnt-IRL framework using a pairwise penalty on trajectories. Empirical results in a highway driving and grid-world problems indicate that MESSI is able to take advantage of the unsupervised trajectories and improve the performance of MaxEnt-IRL.
2014
- Tomáš Kocák, Gergely Neu, Michal Valko, Rémi Munos: Efficient learning by implicit exploration in bandit problems with side observations, in Neural Information Processing Systems (NeurIPS 2014)
arXiv preprint
bibtex
talk
poster abstract
We consider online learning problems under a partial observability model capturing situations where the information conveyed to the learner is between full information and bandit feedback. In the simplest variant, we assume that in addition to its own loss, the learner also gets to observe losses of some other actions. The revealed losses depend on the learner's action and a directed observation system chosen by the environment. For this setting, we propose the first algorithm that enjoys near-optimal regret guarantees without having to know the observation system before selecting its actions. Along similar lines, we also define a new partial information setting that models online combinatorial optimization problems where the feedback received by the learner is between semi-bandit and full feedback. As the predictions of our first algorithm cannot be always computed efficiently in this setting, we propose another algorithm with similar properties and with the benefit of always being computationally efficient, at the price of a slightly more complicated tuning mechanism. Both algorithms rely on a novel exploration strategy called implicit exploration, which is shown to be more efficient both computationally and information-theoretically than previously studied exploration strategies for the problem.
- Alexandra Carpentier, Michal Valko: Extreme bandits, in Neural Information Processing Systems (NeurIPS 2014)
arXiv preprint
bibtex
poster abstract
In many areas of medicine, security, and life sciences, we want to allocate limited resources to different sources in order to detect extreme values. In this paper, we study an efficient way to allocate these resources sequentially under limited feedback. While sequential design of experiments is well studied in bandit theory, the most commonly optimized property is the regret with respect to the maximum mean reward. However, in other problems such as network intrusion detection, we are interested in detecting the most extreme value output by the sources. Therefore, in our work we study extreme regret which measures the efficiency of an algorithm compared to the oracle policy selecting the source with the heaviest tail. We propose the ExtremeHunter algorithm, provide its analysis, and evaluate it empirically on synthetic and real-world experiments.
- Gergely Neu, Michal Valko: Online combinatorial optimization with stochastic decision sets and adversarial losses, in Neural Information Processing Systems (NeurIPS 2014)
arXiv preprint
bibtex
talk
poster abstract
Most work on sequential learning assumes a fixed set of actions that are available all the time. However, in practice, actions can consist of picking subsets of readings from sensors that may break from time to time, road segments that can be blocked or goods that are out of stock. In this paper we study learning algorithms that are able to deal with stochastic availability of such unreliable composite actions. We propose and analyze algorithms based on the Follow-The-Perturbed-Leader prediction method for several learning settings differing in the feedback provided to the learner. Our algorithms rely on a novel loss estimation technique that we call Counting Asleep Times. We deliver regret bounds for our algorithms for the previously studied full information and (semi-)bandit settings, as well as a natural middle point between the two that we call the restricted information setting. A special consequence of our results is a significant improvement of the best known performance guarantees achieved by an efficient algorithm for the sleeping bandit problem with stochastic availability. Finally, we evaluate our algorithms empirically and show their improvement over the known approaches.
- Michal Valko, Rémi Munos, Branislav Kveton, Tomáš Kocák: Spectral bandits for smooth graph functions, in International Conference on Machine Learning (ICML 2014)
bibtex
slides
poster abstract
Smooth functions on graphs have wide applications in manifold and semi-supervised learning. In this paper, we study a bandit problem where the payoffs of arms are smooth on a graph. This framework is suitable for solving online learning problems that involve graphs, such as content-based recommendation. In this problem, each item we can recommend is a node and its expected rating is similar to its neighbors. The goal is to recommend items that have high expected ratings. We aim for the algorithms where the cumulative regret with respect to the optimal policy would not scale poorly with the number of nodes. In particular, we introduce the notion of an effective dimension, which is small in real-world graphs, and propose two algorithms for solving our problem that scale linearly and sublinearly in this dimension. Our experiments on real-world content recommendation problem show that a good estimator of user preferences for thousands of items can be learned from just tens of nodes evaluations.
- Tomáš Kocák, Michal Valko, Rémi Munos, Shipra Agrawal: Spectral Thompson sampling, in AAAI Conference on Artificial Intelligence (AAAI 2014)
arXiv preprint
bibtex
slides
poster abstract
Thompson Sampling (TS) has surged a lot of interest due to its good empirical performance, in particular in the computational advertising. Though successful, the tools for its performance analysis appeared only recently. In this paper, we describe and analyze SpectralTS algorithm for a bandit problem, where the payoffs of the choices are smooth given an underlying graph. In this setting, each choice is a node of a graph and the expected payoffs of the neighboring nodes are assumed to be similar. Although the setting has application both in recommender systems and advertising, the traditional algorithms would scale poorly with the number of choices. For that purpose we consider an effective dimension d, which is small in real-world graphs. We deliver the analysis showing that the regret of SpectralTS scales as d$\backslash$sqrt(T $\backslash$ln N) with high probability, where T is the time horizon and N is the number of choices. Since a d$\backslash$sqrt(T $\backslash$ln N) regret is comparable to the known results, SpectralTS offers a computationally more efficient alternative. We also show that our algorithm is competitive on both synthetic and real-world data.
- Philippe Preux, Rémi Munos, Michal Valko: Bandits attack function optimization, in IEEE Congress on Evolutionary Computation (CEC 2014)
bibtex abstract
We consider function optimization as a sequential decision making problem under the budget constraint. Such constraint limits the number of objective function evaluations allowed during the optimization. We consider an algorithm inspired by a continuous version of a multi-armed bandit problem which attacks this optimization problem by solving the tradeoff between exploration (initial quasi-uniform search of the domain) and exploitation (local optimization around the potentially global maxima). We introduce the so-called Simultaneous Optimistic Optimization (SOO), a deterministic algorithm that works by domain partitioning. The benefit of such an approach are the guarantees on the returned solution and the numerical eficiency of the algorithm. We present this machine learning rooted approach to optimization, and provide the empirical assessment of SOO on the CEC’2014 competition on single objective real-parameter numerical optimization testsuite.
- Tomáš Kocák, Michal Valko, Rémi Munos, Branislav Kveton, Shipra Agrawal: Spectral bandits for smooth graph functions with applications in recommender systems, in AAAI Workshop on Sequential Decision-Making with Big Data (AAAI 2014 - SDMBD)
arXiv preprint
bibtex abstract
Smooth functions on graphs have wide applications in manifold and semi-supervised learning. In this paper, we study a bandit problem where the payoffs of arms are smooth on a graph. This framework is suitable for solving online learning problems that involve graphs, such as content-based recommendation. In this problem, each recommended item is a node and its expected rating is similar to its neighbors. The goal is to recommend items that have high expected ratings. We aim for the algorithms where the cumulative regret would not scale poorly with the number of nodes. In particular, we introduce the notion of an effective dimension, which is small in real-world graphs, and propose two algorithms for solving our problem that scale linearly in this dimension. Our experiments on real-world content recommendation problem show that a good estimator of user preferences for thousands of items can be learned from just tens nodes evaluations.
2013
- Michal Valko, Alexandra Carpentier, Rémi Munos: Stochastic simultaneous optimistic optimization, in International Conference on Machine Learning (ICML 2013)
arXiv preprint
bibtex
demo
code
code in R
slides
poster
video
talk abstract
We study the problem of global maximization of a function f given a finite number of evaluations perturbed by noise. We consider a very weak assumption on the function, namely that it is locally smooth (in some precise sense) with respect to some semi-metric, around one of its global maxima. Compared to previous works on bandits in general spaces (Kleinberg et al., 2008; Bubeck et al., 2011a) our algorithm does not require the knowledge of this semi-metric. Our algorithm, StoSOO, follows an optimistic strategy to iteratively construct upper confidence bounds over the hierarchical partitions of the function domain to decide which point to sample next. A finite-time analysis of StoSOO shows that it performs almost as well as the best specifically-tuned algorithms even though the local smoothness of the function is not known.
- Michal Valko, Nathan Korda, Rémi Munos, Ilias Flaounas, Nello Cristianini: Finite-time analysis of kernelised contextual bandits, in Uncertainty in Artificial Intelligence (UAI 2013) (JFPDA 2013)
arXiv preprint
bibtex
poster
spotlight
code abstract
We tackle the problem of online reward maximisation over a large finite set of actions described by their contexts. We focus on the case when the number of actions is too big to sample all of them even once. However we assume that we have access to the similarities between actions' contexts and that the expected reward is an arbitrary linear function of the contexts' images in the related reproducing kernel Hilbert space (RKHS). We propose KernelUCB, a kernelised UCB algorithm, and give a cumulative regret bound through a frequentist analysis. For contextual bandits, the related algorithm GP-UCB turns out to be a special case of our algorithm, and our finite-time analysis improves the regret bound of GP-UCB for the agnostic case, both in the terms of the kernel-dependent quantity and the RKHS norm of the reward function. Moreover, for the linear kernel, our regret bound matches the lower bound for contextual linear bandits.
- Branislav Kveton, Michal Valko: Learning from a single labeled face and a stream of unlabeled data, in IEEE International Conference on Automatic Face and Gesture Recognition (FG 2013) [spotlight]
arXiv preprint
bibtex abstract
Face recognition from a single image per person is a challenging problem because the training sample is extremely small. We consider a variation of this problem. In our problem, we recognize only one person, and there are no labeled data for any other person. This setting naturally arises in authentication on personal computers and mobile devices, and poses additional challenges because it lacks negative examples. We formalize our problem as one-class classification, and propose and analyze an algorithm that learns a non-parametric model of the face from a single labeled image and a stream of unlabeled data. In many domains, for instance when a person interacts with a computer with a camera, unlabeled data are abundant and easy to utilize. This is the first paper that investigates how these data can help in learning better models in the single-image-per-person setting. Our method is evaluated on a dataset of 43 people and we show that these people can be recognized 90\% of time at nearly zero false positives. This recall is 25+\% higher than the recall of our best performing baseline. Finally, we conduct a comprehensive sensitivity analysis of our algorithm and provide a guideline for setting its parameters in practice.
- Miloš Hauskrecht, Iyad Batal, Michal Valko, Shyam Visweswaran, Gregory F. Cooper, Gilles Clermont: Outlier detection for patient monitoring and alerting, in Journal of Biomedical Informatics (JBI 2013)
bibtex abstract
We develop and evaluate a data-driven approach for detecting unusual (anomalous) patient-management decisions using past patient cases stored in electronic health records (EHRs). Our hypothesis is that a patient-management decision that is unusual with respect to past patient care may be due to an error and that it is worthwhile to generate an alert if such a decision is encountered. We evaluate this hypothesis using data obtained from EHRs of 4486 post-cardiac surgical patients and a subset of 222 alerts generated from the data. We base the evaluation on the opinions of a panel of experts. The results of the study support our hypothesis that the outlier-based alerting can lead to promising true alert rates. We observed true alert rates that ranged from 25\% to 66\% for a variety of patient-management actions, with 66\% corresponding to the strongest outliers.
2012
- Michal Valko, Mohammad Ghavamzadeh, Alessandro Lazaric: Semi-supervised apprenticeship learning, in Journal of Machine Learning Research Workshop and Conference Proceedings: (EWRL 2012)
bibtex
talk
poster abstract
In apprenticeship learning we aim to learn a good policy by observing the behavior of an expert or a set of experts. In particular, we consider the case where the expert acts so as to maximize an unknown reward function defined as a linear combination of a set of state features. In this paper, we consider the setting where we observe many sample trajectories (i.e., sequences of states) but only one or a few of them are labeled as experts' trajectories. We investigate the conditions under which the remaining unlabeled trajectories can help in learning a policy with a good performance. In particular, we define an extension to the max-margin inverse reinforcement learning proposed by Abbeel and Ng (2004) where, at each iteration, the max-margin optimization step is replaced by a semi-supervised optimization problem which favors classifiers separating clusters of trajectories. Finally, we report empirical results on two grid-world domains showing that the semi-supervised algorithm is able to output a better policy in fewer iterations than the related algorithm that does not take the unlabeled trajectories into account.
2011
- Michal Valko, Branislav Kveton, Hamed Valizadegan, Gregory F. Cooper, Miloš Hauskrecht: Conditional anomaly detection with soft harmonic functions, in International Conference on Data Mining (ICDM 2011)
bibtex abstract
In this paper, we consider the problem of conditional anomaly detection that aims to identify data instances with an unusual response or a class label. We develop a new non-parametric approach for conditional anomaly detection based on the soft harmonic solution, with which we estimate the confidence of the label to detect anomalous mislabeling. We further regularize the solution to avoid the detection of isolated examples and examples on the boundary of the distribution support. We demonstrate the efficacy of the proposed method on several synthetic and UCI ML datasets in detecting unusual labels when compared to several baseline approaches. We also evaluate the performance of our method on a real-world electronic health record dataset where we seek to identify unusual patient-management decisions.
- Thomas C. Hart, Patricia M. Corby, Miloš Hauskrecht, Ok Hee Ryu, Richard Pelikan, Michal Valko, Maria B. Oliveira, Gerald T. Hoehn, Walter A. Bretz: Identification of microbial and proteomic biomarkers in early childhood caries, in International Journal of Dentistry (IJD 2011)
bibtex abstract
The purpose of this study was to provide a univariate and multivariate analysis of genomic microbial data and salivary mass-spectrometry proteomic profiles for dental caries outcomes. In order to determine potential useful biomarkers for dental caries, a multivariate classification analysis was employed to build predictive models capable of classifying microbial and salivary sample profiles with generalization performance. We used high-throughput methodologies including multiplexed microbial arrays and SELDI-TOF-MS profiling to characterize the oral flora and salivary proteome in 204 children aged 1-8 years (n = 118 caries-free, n = 86 caries-active). The population received little dental care and was deemed at high risk for childhood caries. Findings of the study indicate that models incorporating both microbial and proteomic data are superior to models of only microbial or salivary data alone. Comparison of results for the combined and independent data suggests that the combination of proteomic and microbial sources is beneficial for the classification accuracy and that combined data lead to improved predictive models for caries-active and caries-free patients. The best predictive model had a 6\% test error, >92\% sensitivity, and >95\% specificity. These findings suggest that further characterization of the oral microflora and the salivary proteome associated with health and caries may provide clinically useful biomarkers to better predict future caries experience.
- Michal Valko: Adaptive graph-based algorithms for conditional anomaly detection and semi-supervised learning, PhD thesis, (PITT 2011)
bibtex
proposal
talk abstract
We develop graph-based methods for semi-supervised learning based on label propagation on a data similarity graph. When data is abundant or arrive in a stream, the problems of computation and data storage arise for any graph-based method. We propose a fast approximate online algorithm that solves for the harmonic solution on an approximate graph. We show, both empirically and theoretically, that good behavior can be achieved by collapsing nearby points into a set of local representative points that minimize distortion. Moreover, we regularize the harmonic solution to achieve better stability properties. We also present graph-based methods for detecting conditional anomalies and apply them to the identification of unusual clinical actions in hospitals. Our hypothesis is that patient-management actions that are unusual with respect to the past patients may be due to errors and that it is worthwhile to raise an alert if such a condition is encountered. Conditional anomaly detection extends standard unconditional anomaly framework but also faces new problems known as fringe and isolated points. We devise novel nonparametric graph-based methods to tackle these problems. Our methods rely on graph connectivity analysis and soft harmonic solution. Finally, we conduct an extensive human evaluation study of our conditional anomaly methods by 15 experts in critical care.
- Michal Valko, Hamed Valizadegan, Branislav Kveton, Gregory F. Cooper, Miloš Hauskrecht: Conditional anomaly detection using soft harmonic functions: An application to clinical alerting, in International Conference on Machine Learning (Workshop on Machine Learning for Global Challenges ICML 2011 - Global)
bibtex
poster
spotlight abstract
Timely detection of concerning events is an important problem in clinical practice. In this paper, we consider the problem of conditional anomaly detection that aims to identify data instances with an unusual response, such as the omission of an important lab test. We develop a new non-parametric approach for conditional anomaly detection based on the soft harmonic solution, with which we estimate the confidence of the label to detect anomalous mislabeling. We further regularize the solution to avoid the detection of isolated examples and examples on the boundary of the distribution support. We demonstrate the efficacy of the proposed method in detecting unusual labels on a real-world electronic health record dataset and compare it to several baseline approaches.
2010
- Michal Valko, Branislav Kveton, Ling Huang, Daniel Ting: Online semi-supervised learning on quantized graphs, in Uncertainty in Artificial Intelligence (UAI 2010)
arXiv preprint
bibtex
Video: Adaptation
Video: OfficeSpace
spotlight
poster abstract
In this paper, we tackle the problem of online semi-supervised learning (SSL). When data arrive in a stream, the dual problems of computation and data storage arise for any SSL method. We propose a fast approximate online SSL algorithm that solves for the harmonic solution on an approximate graph. We show, both empirically and theoretically, that good behavior can be achieved by collapsing nearby points into a set of local "representative points" that minimize distortion. Moreover, we regularize the harmonic solution to achieve better stability properties. We apply our algorithm to face recognition and optical character recognition applications to show that we can take advantage of the manifold structure to outperform the previous methods. Unlike previous heuristic approaches, we show that our method yields provable performance bounds.
- Branislav Kveton, Michal Valko, Ali Rahimi, Ling Huang: Semi-supervised learning with max-margin graph cuts, in International Conference on Artificial Intelligence and Statistics (AISTATS 2010)
arXiv preprint
bibtex abstract
This paper proposes a novel algorithm for semisupervised learning. This algorithm learns graph cuts that maximize the margin with respect to the labels induced by the harmonic function solution. We motivate the approach, compare it to existing work, and prove a bound on its generalization error. The quality of our solutions is evaluated on a synthetic problem and three UCI ML repository datasets. In most cases, we outperform manifold regularization of support vector machines, which is a state-of-the-art approach to semi-supervised max-margin learning.
- Miloš Hauskrecht, Michal Valko, Shyam Visweswaran, Iyad Batal, Gilles Clermont, Gregory Cooper: Conditional outlier detection for clinical alerting, in Annual American Medical Informatics Association conference (AMIA 2010) [Homer Warner Best Paper]
bibtex abstract
We develop and evaluate a data-driven approach for detecting unusual (anomalous) patient-management actions using past patient cases stored in an electronic health record (EHR) system. Our hypothesis is that patient-management actions that are unusual with respect to past patients may be due to a potential error and that it is worthwhile to raise an alert if such a condition is encountered. We evaluate this hypothesis using data obtained from the electronic health records of 4,486 post-cardiac surgical patients. We base the evaluation on the opinions of a panel of experts. The results support that anomaly-based alerting can have reasonably low false alert rates and that stronger anomalies are correlated with higher alert rates.
- Branislav Kveton, Michal Valko, Matthai Phillipose, Ling Huang: Online semi-supervised perception: Real-time learning without explicit feedback, in IEEE Online Learning for Computer Vision Workshop in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2010 - OLCV) [best paper Google]
Award
arXiv preprint
bibtex
talk abstract
This paper proposes an algorithm for real-time learning without explicit feedback. The algorithm combines the ideas of semi-supervised learning on graphs and online learning. In particular, it iteratively builds a graphical representation of its world and updates it with observed examples. Labeled examples constitute the initial bias of the algorithm and are provided offline, and a stream of unlabeled examples is collected online to update this bias. We motivate the algorithm, discuss how to implement it efficiently, prove a regret bound on the quality of its solutions, and apply it to the problem of real-time face recognition. Our recognizer runs in real time, and achieves superior precision and recall on 3 challenging video datasets.
- Michal Valko, Miloš Hauskrecht: Feature importance analysis for patient management decisions, in International Congress on Medical Informatics (MEDINFO 2010)
bibtex abstract
The objective of this paper is to understand what characteris-tics and features of clinical data influence physician.s deci-sion about ordering laboratory tests or prescribing medica-tions the most. We conduct our analysis on data and decisions extracted from electronic health records of 4486 post-surgical cardiac patients. The summary statistics for 335 different lab order decisions and 407 medication decisions are reported. We show that in many cases, physician.s lab-order and medication decisions are predicted well by simple patterns such as last value of a single test result, time since a certain lab test was ordered or time since certain procedure was executed.
{kind=link}
2008
- Michal Valko, Gregory Cooper, Amy Seybert, Shyam Visweswaran, Melissa Saul, Miloš Hauskrecht: Conditional anomaly detection methods for patient-management alert systems, in International Conference on Machine Learning (Workshop on Machine Learning Health Care Applications ICML-2008 - MLHealth)
bibtex
talk abstract
Anomaly detection methods can be very useful in identifying unusual or interesting patterns in data. A recently proposed conditional anomaly detection framework extends anomaly detection to the problem of identifying anomalous patterns on a subset of attributes in the data. The anomaly always depends (is conditioned) on the value of remaining attributes. The work presented in this paper focuses on instance-based methods for detecting conditional anomalies. The methods rely on the distance metric to identify examples in the dataset that are most critical for detecting the anomaly. We investigate various metrics and metric learning methods to optimize the performance of the instance-based anomaly detection methods. We show the benefits of the instance-based methods on two real-world detection problems: detection of unusual admission decisions for patients with the community-acquired pneumonia and detection of unusual orders of an HPF4 test that is used to confirm Heparin induced thrombocytopenia - a life-threatening condition caused by the Heparin therapy.
- Michal Valko, Miloš Hauskrecht: Distance metric learning for conditional anomaly detection, (FLAIRS 2008)
bibtex
talk abstract
Anomaly detection methods can be very useful in identifying unusual or interesting patterns in data. A recently proposed conditional anomaly detection framework extends anomaly detection to the problem of identifying anomalous patterns on a subset of attributes in the data. The anomaly always depends (is conditioned) on the value of remaining attributes. The work presented in this paper focuses on instance-based methods for detecting conditional anomalies. The methods depend heavily on the distance metric that lets us identify examples in the dataset that are most critical for detecting the anomaly. To optimize the performance of the anomaly detection methods we explore and study metric learning methods. We evaluate the quality of our methods on the Pneumonia PORT dataset by detecting unusual admission decisions for patients with the community-acquired pneumonia. The results of our metric learning methods show an improved detection performance over standard distance metrics, which is very promising for building automated anomaly detection systems for variety of intelligent monitoring applications.
- Michal Valko, Richard Pelikan, Miloš Hauskrecht: Learning predictive models for combinations of heterogeneous proteomic data sources, in AMIA Summit on Translational Bioinformatics (STB 2008) [outstanding paper]
bibtex
talk abstract
Multiple technologies that measure expression levels of protein mixtures in the human body offer a potential for detection and understanding the disease. The recent increase of these technologies prompts researchers to evaluate the individual and combined utility of data generated by the technologies. In this work, we study two data sources to measure the expression of protein mixtures in the human body: whole-sample MS profiling and multiplexed protein arrays. We investigate the individual and combined utility of these technologies by learning and testing a variety of classification models on the data from a pancreatic cancer study. We show that for the combination of these two (heterogeneous) datasets, classification models that work well on one of them individually fail on the combination of the two datasets. We study and propose a class of model fusion methods that acknowledge the differences and try to reap most of the benefits from their combination.
2007
- Miloš Hauskrecht, Michal Valko, Branislav Kveton, Shyam Visweswaran, Gregory Cooper: Evidence-based anomaly detection in clinical domains, in Annual American Medical Informatics Association conference (AMIA 2007) [nominated for the best paper award]
bibtex
talk abstract
Anomaly detection methods can be very useful in identifying interesting or concerning events. In this work, we develop and examine new probabilistic anomaly detection methods that let us evaluate management decisions for a specific patient and identify those decisions that are highly unusual with respect to patients with the same or similar condition. The statistics used in this detection are derived from probabilistic models such as Bayesian networks that are learned from a database of past patient cases. We evaluate our methods on the problem of detection of unusual hospitalization patterns for patients with community acquired pneumonia. The results show very encouraging detection performance with 0.5 precision at 0.53 recall and give us hope that these techniques may provide the basis of intelligent monitoring systems that alert clinicians to the occurrence of unusual events or decisions.
2006
- Wendy W. Chapman, John N. Dowling, Gregory F. Cooper, Miloš Hauskrecht, Michal Valko: A comparison of chief complaints and emergency department reports for identifying patients with acute lower respiratory syndrome, in Proceedings of the National Syndromic Surveillance Conference (ISDS 2006)
bibtex abstract
Automated syndromic surveillance systems often classify patients into syndromic categories based on free-text chief complaints. Chief complaints (CC) demonstrate low to moderate sensitivity in identifying syndromic cases. Emergency Department (ED) reports promise more detailed clinical information that may increase sensitivity of detection.
- Miloš Hauskrecht, Richard Pelikan, Michal Valko, James Lyons-Weiler: Feature selection and dimensionality reduction in genomics and proteomics, in Fundamentals of Data Mining in Genomics and Proteomics, eds. Berrar, Dubitzky, Granzow. Springer (2006)
Fundamentals of Data Mining in Genomics and Proteomics
bibtex abstract
Finding reliable, meaningful patterns in data with high numbers of attributes can be extremely difficult. Feature selection helps us to decide what attributes or combination of attributes are most important for finding these patterns. In this chapter, we study feature selection methods for building classification models from high-throughput genomic (microarray) and proteomic (mass spectrometry) data sets. Thousands of feature candidates must be analyzed, compared and combined in such data sets. We describe the basics of four different approaches used for feature selection and illustrate their effects on an MS cancer proteomic data set. The closing discussion provides assistance in performing an analysis in high-dimensional genomic and proteomic data.
2005
- Michal Valko, Nuno C. Marques, Marco Castelani: Evolutionary feature selection for spiking neural network pattern classifiers, in Proceedings of Portuguese Conference on Artificial Intelligence (EPIA 2005), eds. Bento et al., IEEE, pages 24-32
PDF
arXiv preprint
bibtex abstract
This paper presents an application of the biologically realistic JASTAP neural network model to classification tasks. The JASTAP neural network model is presented as an alternative to the basic multi-layer perceptron model. An evolutionary procedure previously applied to the simultaneous solution of feature selection and neural network training on standard multi-layer perceptrons is extended with JASTAP model. Preliminary results on IRIS standard data set give evidence that this extension allows the use of smaller neural networks that can handle noisier data without any degradation in classification accuracy.
- Michal Valko: Evolving neural networks for statistical decision theory, Comenius University, Bratislava, 2005 (master thesis) (2005) Advisor: Radoslav Harman
bibtex
talk abstract
Real biological networks are able to make decisions. We will show that this behavior can be observed even in some simple architectures of biologically plausible neural models. The great interest of this thesis is also to contribute to methods of statistical decision theory by giving a lead how to evolve the neural networks to solve miscellaneous decision tasks.