

















Software & Code
- Llama 3 Python — SOTA open foundation model. Lead for Post-training and Alignment.
- rlberry Python — Reinforcement learning library for research and education with reproducibility tools. [Zenodo 2024]
- HalfHop Python — Graph upsampling approach for slowing down message passing. Integrated into PyTorch Geometric. [ICML 2023]
- BYOL Python — Bootstrap Your Own Latent - self-supervised learning without negative pairs. NeurIPS 2020 oral (1% acceptance rate). [NeurIPS 2020]
- DPPy Python — Python library for sampling and learning with determinantal point processes. [JMLR 2019]
- D-TTTS Python — Simple dynamic bandit-based algorithm for hyper-parameter tuning. [ICML 2019 Workshop]
- SQUEAK Python — Streaming kernel matrix approximation via ridge leverage score sampling in a single pass. [AISTATS 2017]
- Bayesian Policy Gradient MATLAB — Bayesian policy gradient and actor-critic algorithms for reinforcement learning. [JMLR 2016]
- POO R — Parallel Optimistic Optimization for black-box optimization of noisy functions with unknown smoothness. [NeurIPS 2015]
- StoSOO MATLAB — Stochastic Simultaneous Optimistic Optimization - global maximization without knowing the smoothness. [ICML 2013]
- KernelUCB MATLAB — Kernelised contextual bandits with finite-time regret analysis. [UAI 2013]
- PlaSyn C++ — Plastic Synapses - computational neuroscience simulator modeling basic learning functions at synaptic level. [2003-2004]
Current Research
RLHF and LLM Alignment Active
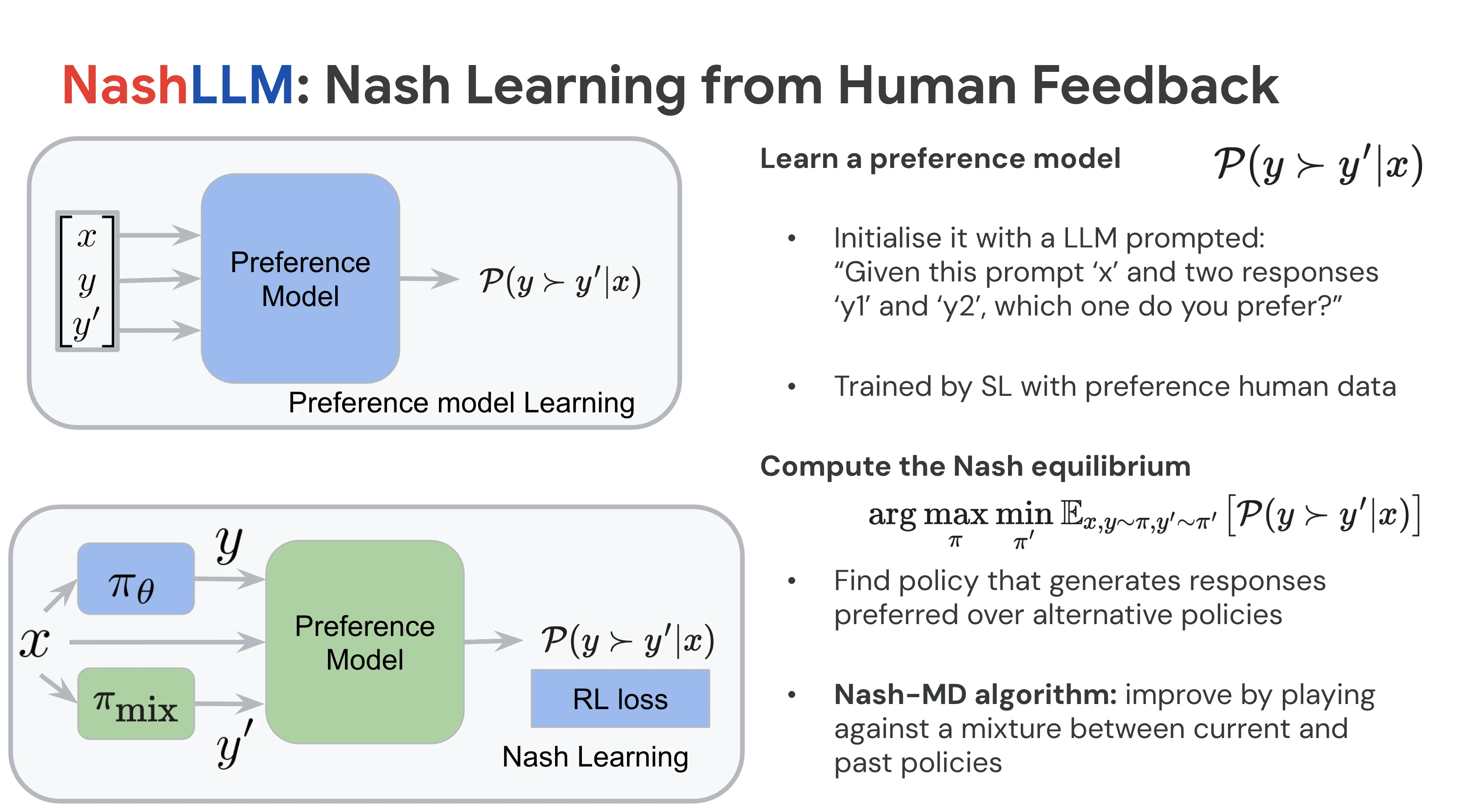
We design the algorithms and theory that take a pretrained language model and turn it into one a human actually wants to interact with. The headline contribution is Nash Learning from Human Feedback (NLHF), which reframes alignment as finding the Nash equilibrium of a two-player preference game instead of maximizing a learned scalar reward. NLHF sidesteps the reward-model bottleneck that dominates classical RLHF (reward hacking, intransitive preferences, narrow coverage) and stays well-defined whenever a preference oracle exists, even when no consistent reward function does. Around this central idea we have built (i) a unified theoretical framework that places DPO, IPO, SLiC, and RLHF as special cases of a single convex family (GPO / IPO), (ii) accelerated Nash policy optimization with provable mirror-prox convergence rates, (iii) multi-sample and proximal-point variants that go beyond single pairwise comparisons, (iv) online preference optimization and decoding-time realignment to close the online-offline gap, and (v) optimal experimental design for reward modeling itself. The line of work fed directly into the post-training and alignment stack of Llama 3.
- NLHF (ICML 2024): alignment as a two-player game; finds the Nash policy of a learned preference model without ever training a scalar reward model
- IPO / general theoretical paradigm (AISTATS 2024): unified analytical lens placing DPO, RLHF, and identity-preference optimization in a single family, with explicit regularization trade-offs
- GPO (ICML 2024 spotlight): generalized preference optimization, a convex family of offline losses that subsumes DPO, IPO, and SLiC and exposes how each enforces regularization
- Online preference optimisation (ICML 2024 spotlight): closes the online-offline performance gap and explains why on-policy preference data matters
- Mirror-prox NLHF (COLT 2025): accelerated Nash policy optimization with provable convergence; tighter rates than Nash-MD for the same oracle
- Proximal-point NLHF and multi-sample preference optimization: stable, tunable post-training that extends beyond single pairwise comparisons (NeurIPS 2024)
- Decoding-time realignment: control the degree of alignment at inference by mixing aligned and base model logits, no retraining required
- Optimal design for reward modeling in RLHF: when one does want a reward model, choose preference pairs to maximize statistical efficiency
- Llama 3 (2024): core post-training and alignment contributor on Meta's flagship open model
Zero-Sum Games and Imperfect Information Active
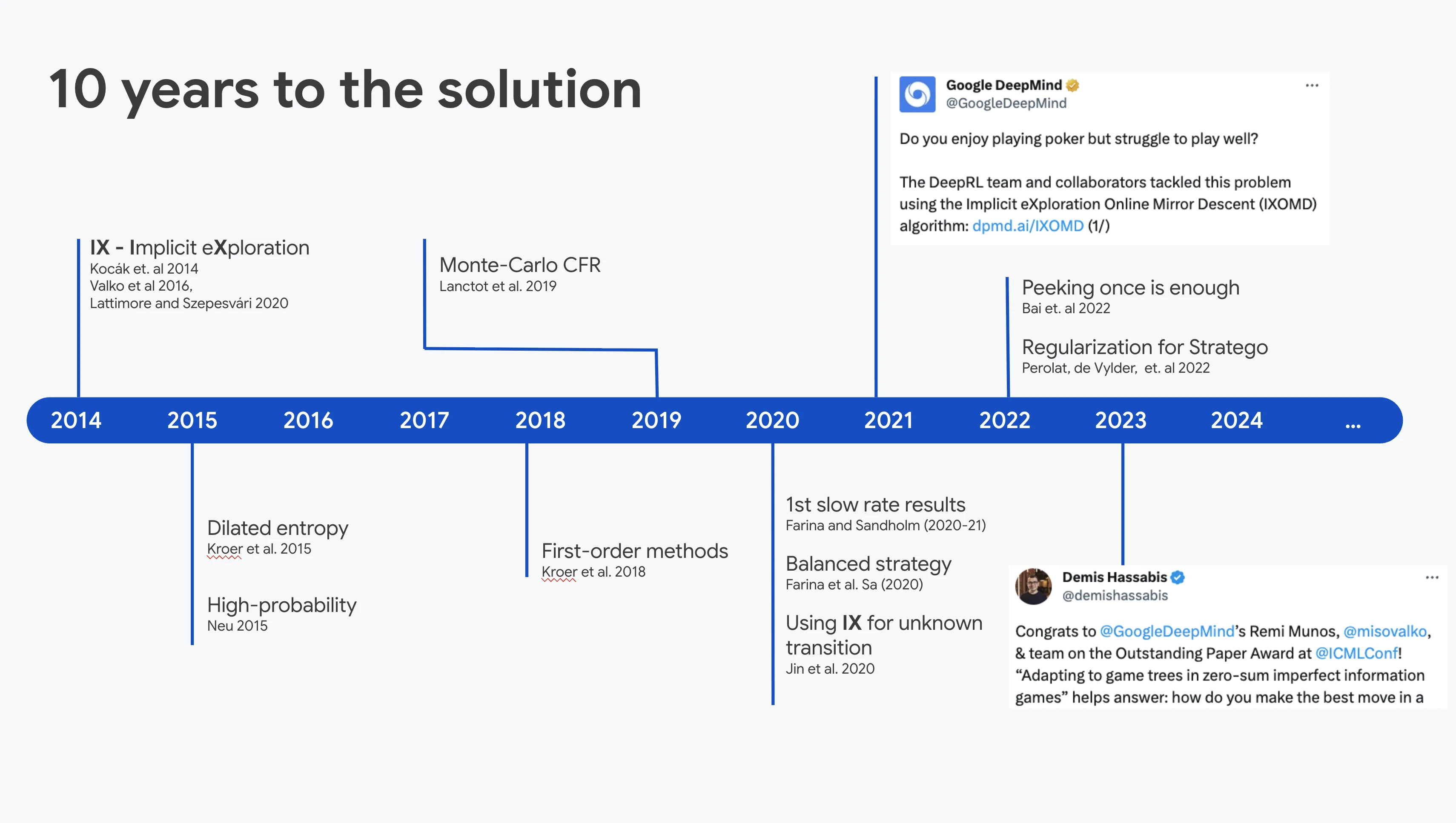
We design provably efficient learning algorithms for two-player zero-sum games with imperfect information, the setting that covers poker, negotiation, security games, and adversarial robustness. The hard part is that the learner only sees bandit feedback along trajectories of the game tree, not the full payoff matrix, and the size of an extensive-form game explodes with horizon and private information. Our line of work attacks this on three fronts. First, model-free algorithms that achieve sample complexity polynomial in the relevant game-tree parameters under partial observability with perfect recall. Second, algorithms that adapt their regret to the actual shape of the game tree rather than worst-case bounds. Third, last-iterate (not average-iterate) convergence guarantees with bandit feedback, which is what one actually wants when the policy is deployed. The NLHF / Nash-MD line of work in the LLM alignment project grew directly out of these tools.
- Adapting to game trees (ICML 2023 outstanding paper): regret bounds that scale with the actual game-tree structure rather than worst-case size
- Model-free learning for two-player zero-sum POMGs with perfect recall (NeurIPS 2021): provably efficient learning under partial observability
- Last-iterate convergence with bandit feedback (ICML 2025): convergence of the actual deployed policy, not just the time-average, under bandit access
- Local and adaptive mirror descents for extensive-form games (NeurIPS 2024): per-infoset adaptive step sizes that beat uniform mirror descent
- Game-theoretic analysis of multi-agent systems (Nature Machine Intelligence 2021): empirical game theory at scale
- Nash-MD as a bridge between zero-sum games and LLM alignment: the same Nash-equilibrium machinery powers NLHF preference optimization
Sample efficient Monte-Carlo tree search Active
2011 – presentMonte-Carlo tree search powered the breakthroughs in computer Go, but the underlying machinery, sequential allocation of a sample budget across a tree of unknown values, is much more general. We work on two sides of it. The first is global black-box optimization of functions that are expensive, non-convex, and have only mild local-smoothness structure; our StoSOO and HOO-style algorithms come with formal regret guarantees and apply directly to hyperparameter tuning. The second is planning in MDPs with a generative model, where our TrailBlazer algorithm adaptively focuses the sample budget on near-optimal branches and gets sample complexity that depends on a problem-dependent near-optimality measure rather than the total tree size. Together with parameter-free and scale-free variants (no need to know the smoothness or the value range in advance), this line of work pushed MCTS from a heuristic into algorithms with provable anytime guarantees.
- StoSOO (ICML 2015): stochastic simultaneous optimistic optimization; provable black-box optimization under only weak local-smoothness assumptions
- TrailBlazer (NIPS 2016 + ICML 2020 adaptive variant): adaptive planning in MDPs with sample complexity that depends on a problem-dependent near-optimality measure, not the whole tree
- Black-box optimization of non-convex functions (NIPS 2015): regret bounds that adapt to the function's near-optimality dimension
- Bartlett-Gabillon-Valko parameter-free and scale-free MCTS (ALT 2019 / ICML 2019): no need to know the smoothness constant or value range upfront
- Derivative-free, multi-fidelity, and adaptive variants (ICLR 2020, CEC 2014, ICML 2013): MCTS extensions that match modern hyperparameter-tuning workloads
Posterior Sampling and Bayesian RL Completed

Posterior sampling, sometimes called Thompson sampling in the bandit literature, is the elegant alternative to UCB-style exploration. Maintain a posterior over the unknown environment and act greedily with respect to a single sample from it. In RL, posterior sampling has been widely loved for its empirical performance but lagged behind bonus-based methods in worst-case theoretical guarantees. We close this gap. Our contributions span (i) optimistic posterior sampling for tabular MDPs with tight, near-minimax regret bounds (Bayes-UCBVI and friends), (ii) model-free posterior sampling via learning-rate randomization, which inherits Thompson sampling''s optimism without ever building a model, (iii) sharp non-asymptotic deviation bounds for weighted sums of Dirichlet random variables and new bounds on the cumulant generating function of Dirichlet processes (the probabilistic machinery underneath Bayesian-bootstrap analyses), and (iv) downstream applications including fast rates for maximum-entropy exploration and demonstration-regularized RL. The Dirichlet bounds are reusable across Bayesian-bootstrap algorithms beyond RL.
- Optimistic Posterior Sampling for RL (NeurIPS 2022): first near-minimax regret bounds for posterior sampling in tabular MDPs
- Bayes-UCBVI / Dirichlet weighted sum bounds (ICML 2022): novel sharp non-asymptotic deviation inequalities that close the gap to UCB-style algorithms
- Model-free posterior sampling via learning-rate randomization (NeurIPS 2023): inherits Thompson sampling's optimism without ever maintaining an explicit model
- Fast rates for maximum-entropy exploration (ICML 2023): tightened sample complexity for entropy-regularized exploration
- Demonstration-regularized RL (ICLR 2024): leverages offline demonstrations to accelerate online learning with Bayesian regularization
- New cumulant generating function bounds for Dirichlet processes: reusable probabilistic machinery for Bayesian-bootstrap analyses beyond RL
Self-supervised Learning and BYOL Active

Bootstrap Your Own Latent (BYOL) is a self-supervised representation learning method that, surprisingly, learns strong visual features without ever contrasting against negative pairs. Two networks, an online network and a slow exponential-moving-average target, predict each other's representations of two augmented views of the same image; a stop-gradient on the target side is enough to prevent the collapse that classical analyses had argued was unavoidable without negatives. BYOL reached 74.3% top-1 on ImageNet with a ResNet-50 (79.6% with a larger backbone) and matched or beat contrastive state of the art on transfer and semi-supervised benchmarks at the time of release. The paper has since accumulated more than 11,000 citations and the core "predict your own slow target" recipe became a building block for a whole family of follow-up SSL methods. The line of work below extends BYOL beyond still images to video, graphs, neural recordings, and reinforcement-learning exploration, and pushes on what is actually load-bearing in the recipe.
- BYOL (NeurIPS 2020 oral, 1% accept): self-supervised image representations without negative pairs; 74.3%/79.6% ImageNet linear eval; the seminal "predict your own target" SSL method
- BYOL works even without batch statistics (NeurIPS 2020 SSL workshop): replacing BatchNorm with group-norm + weight standardization recovers vanilla BYOL accuracy, disproving the hypothesis that batch statistics provide an implicit contrastive term
- BraVe (ICCV 2021): broaden-your-views self-supervised video learning; one narrow-window view predicts a broad-context view, enabling cross-modal targets (optical flow, audio, randomly-convolved RGB) and SOTA on UCF101, HMDB51, Kinetics, ESC-50, AudioSet
- MYOW (arXiv 2021): mine-your-own-view across-sample prediction; instead of predicting augmentations of the same sample, predict the latent of a nearby sample, unlocking SSL where rich augmentations are not available (neural recordings, +10% over prior SSL)
- Drop, Swap, and Generate (NeurIPS 2021): SwapVAE applies a BYOL-style approach to neural population activity, learning behaviorally-meaningful generative latents from spike data
- BGRL (ICLR 2022): bootstrapped graph latents scale BYOL to graphs with hundreds of millions of nodes; 2-10x memory reduction over contrastive graph SSL and a KDD Cup 2021 OGB-LSC winning entry
- BYOL-Explore (NeurIPS 2022): the same predict-your-own-latent loss as an intrinsic reward for curiosity-driven exploration; solves DM-HARD-8 without human demonstrations and beats prior agents on the ten hardest Atari exploration games
- BYOL-Hindsight / Curiosity in Hindsight (ICML 2023): noise-robust BYOL-Explore using hindsight representations to factor out the "noisy TV" problem; SOTA on Montezuma's Revenge with sticky actions
- US Patent App. 17/338,777 (2021): self-supervised representation learning using bootstrapped latent representations
Exploration with Intrinsic Motivation Completed
How does an agent learn anything in a world where almost no state gives a reward signal? It explores, and it needs an intrinsic motivation that points it toward what it does not yet understand. This project develops the representation-learning side of that intrinsic motivation. We show that the right intrinsic reward is not novelty in pixel space but novelty in a learned latent space that captures what is actually controllable and predictable. RECODE / "Unlocking the power of representations" applies this idea to long-term novelty-based exploration and sets state-of-the-art on hard-exploration Atari and DM-HARD-8. BYOL-Hindsight / "Curiosity in Hindsight" makes the same machinery robust to stochasticity by factoring out the "noisy TV" trap. Density-based bonuses on learned representations extend it to the reward-free setting, geometric entropic exploration provides a clean information-theoretic justification, and retrieval-augmented RL lets the agent reuse what it has already seen. Together these methods solve sparse-reward problems where bonus-on-pixels methods stall.
- RECODE / Unlocking the power of representations (ICLR 2024): non-parametric clustering-based novelty bonuses on learned embeddings; SOTA on hard-exploration Atari, first agent to finish "Pitfall!"
- BYOL-Hindsight / Curiosity in Hindsight (ICML 2023): hindsight representations make curiosity robust to stochasticity; SOTA on Montezuma's Revenge with sticky actions
- Density-based bonuses on learned representations (ICML 2021 workshop): reward-free exploration in deep RL with provable coverage
- Geometric entropic exploration (JMLR 2025 / ICML 2021): information-theoretic intrinsic reward with clean theoretical footing
- Retrieval-augmented RL (ICML 2022): episodic memory of past trajectories as an exploration prior
- Quantile credit assignment: per-quantile attribution of reward signal, complementary to value-function methods
- Reward-free exploration with kernel-based and goal-oriented variants (ICML 2020): the foundation that the SSP project then sharpened
Off-Policy and Value Function Learning Completed
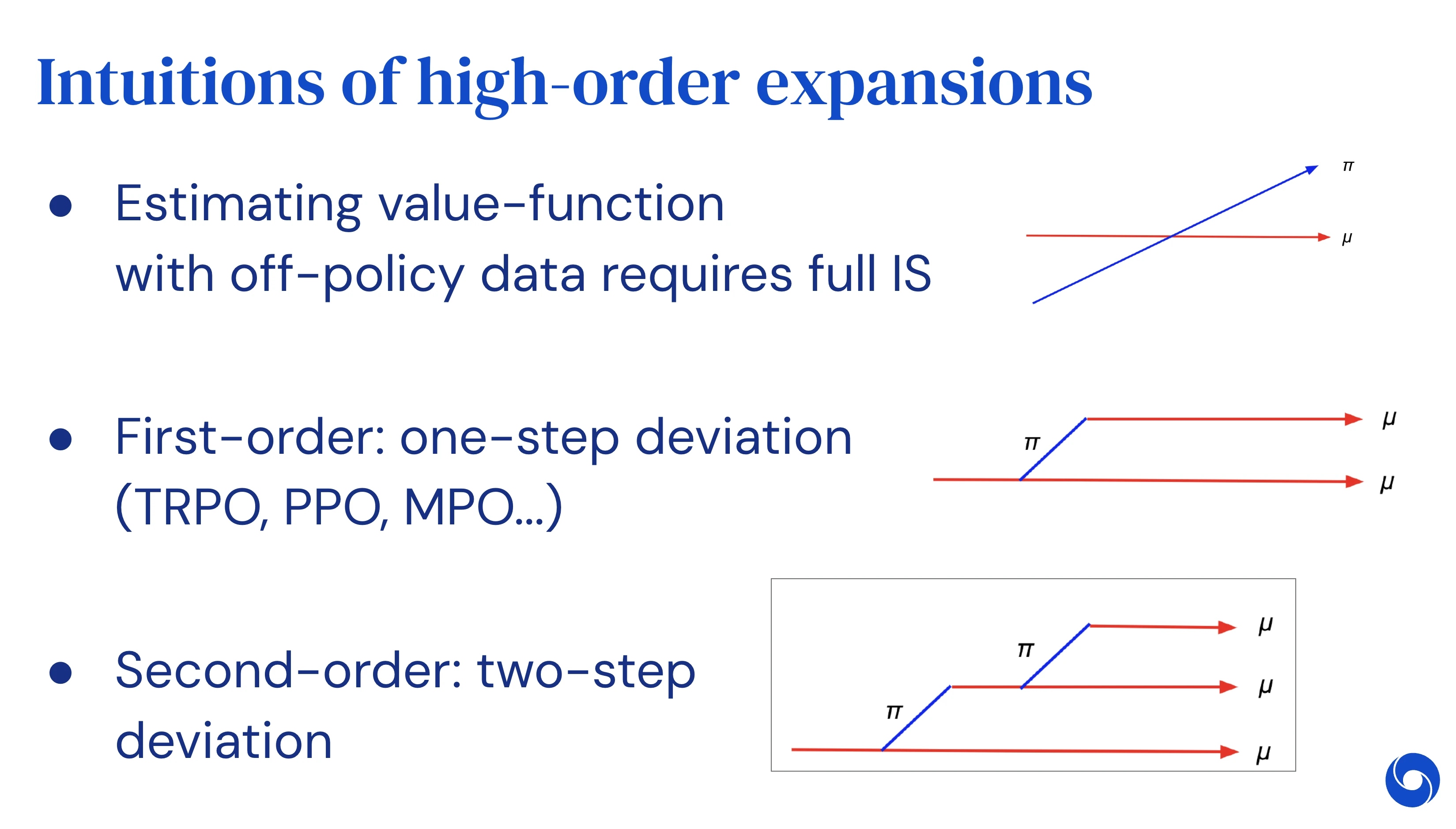
Q-learning, the workhorse of off-policy reinforcement learning, has known pathologies. It overestimates because of the max-over-actions, it is sensitive to the discount factor, it discards information when updating, and many of its "tricks" (TD(λ), retrace, dueling, double-DQN) are essentially heuristics for problems the basic operator does not solve. This project rebuilds the off-policy stack with principled alternatives. UCB Momentum Q-learning corrects the optimization bias of vanilla Q-learning without forgetting past updates. Marginalized operators extend retrace-style methods to a cleaner family with better variance. VA-learning learns the advantage function directly via bootstrapping, with theoretical guarantees comparable to Q-learning but improved sample efficiency, and explains in passing why dueling DQN architectures work. Taylor expansion of discount factors and policy optimization gives meta-RL a unified gradient estimator built on off-policy evaluation, and we revisit Peng''s Q(λ) for modern deep RL settings. The line of work mostly targets the sample efficiency and stability of off-policy deep RL agents, while keeping the math honest.
- UCB Momentum Q-learning (ICML 2021): bias-corrected Q-learning that integrates UCB exploration without discarding past updates
- Unifying gradient estimators for meta-RL via off-policy evaluation (NeurIPS 2021): a single estimator that generalizes prior meta-RL gradients and lowers variance
- Marginalized operators for off-policy RL (AISTATS 2022): a principled family that subsumes Retrace/Tree-Backup and improves variance
- VA-learning (ICML 2023): learn the advantage function directly via bootstrapping; matches Q-learning theory and improves sample efficiency, explains dueling DQN
- Taylor expansion of discount factors and of policy optimization (ICML 2020/2021): unified gradient view on discount-as-regularizer and trust-region methods
- Revisiting Peng's Q(λ) (ICML 2021): the classic eligibility-trace operator works for modern deep RL when one is careful about the off-policy correction
Stochastic Shortest Path and Reward-Free Exploration Completed
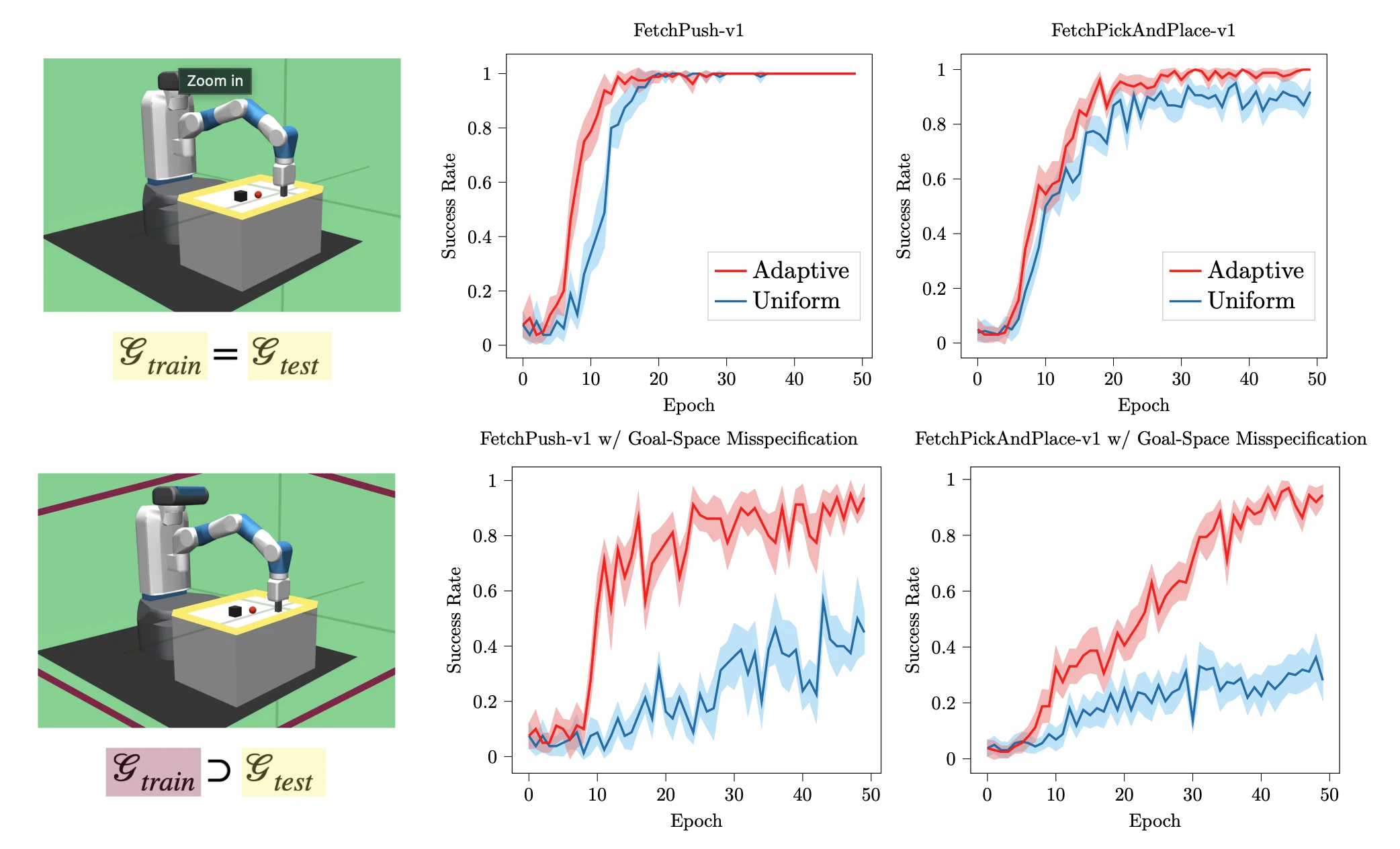
Most regret bounds in RL implicitly assume a fixed horizon and a known reward function. Both assumptions break in the settings that actually matter, like an agent dropped in a new environment, an evaluation pipeline that wants to handle arbitrary downstream tasks, or a goal that may take an unknown number of steps. This project rebuilds the exploration theory for those settings. The stochastic shortest path (SSP) line delivers algorithms with minimax-optimal regret bounds that are parameter-free (no need to know the diameter or the horizon upfront) and approach horizon-free, removing the dependence on the worst-case episode length that polluted earlier bounds. The reward-free line gives provably efficient sample-collection strategies that produce a dataset usable to solve any reward function with near-optimal sample complexity. Around that we have built incremental autonomous exploration that grows the reachable set, goal-oriented exploration that targets explicit reachability goals, and adaptive multi-goal exploration with sharp guarantees on collecting transitions for each of many candidate goals simultaneously.
- Stochastic shortest path with minimax, parameter-free, towards horizon-free regret (NeurIPS 2021): tight bounds with no upfront knowledge of horizon or diameter
- Provably efficient exploration for SSP (NeurIPS 2021): sample-collection strategies with formal guarantees
- No-regret exploration in goal-oriented RL (ICML 2020): goal-directed exploration with regret guarantees, foundational for the SSP line
- Improved sample complexity for incremental autonomous exploration (NeurIPS 2020): grow the reachable set with near-optimal samples
- Adaptive reward-free exploration (ALT 2021): produces a dataset usable to solve any subsequently-specified reward function
- Reward-free exploration beyond finite-horizon (ICML 2020): horizon-free reward-free guarantees
- Adaptive multi-goal exploration (AISTATS 2022): sharp guarantees on collecting transitions for many candidate goals simultaneously
Gaussian Process Bandits Completed

Gaussian process optimization is a textbook example of how theory and practice diverge. Standard GP-UCB has clean regret bounds but its cubic-per-step computation makes it unusable past a few hundred evaluations; scalable variants typically dropped the guarantees. This project rebuilds GP-UCB on top of adaptive sketching, where ridge leverage score sampling maintains an approximate posterior whose effective dimension tracks the true Gaussian process, and we get near-linear per-step cost while preserving the optimal regret rate. The same machinery extends to kernel-based reinforcement learning, where we provide the first finite-time analysis of kernel-based RL in metric spaces (including minimax lower bounds), to non-stationary environments where the function being optimized drifts over time, and to settings where evaluating each candidate multiple times is required to reduce switch costs. The sketching toolkit feeds directly into the DPP and SQUEAK lines.
- GP-UCB with adaptive sketching (COLT 2019): scalable Gaussian process optimization with no regret and near-linear per-step cost via ridge leverage score sampling
- Near-linear time GP optimization (ICML 2020): tightened constants and broader kernel classes
- Scaling Gaussian processes with evaluation reuse (ICML 2022): re-evaluate candidates to reduce switch cost without losing the regret guarantee
- Finite-time analysis of kernel-based RL with minimax lower bounds (ICML 2021): the first matching upper/lower bounds for kernel-based RL in metric spaces
- Kernel-based RL in non-stationary environments (AISTATS 2021): regret bounds that track drift in the underlying value function
Determinantal Point Processes (DPPs) Completed
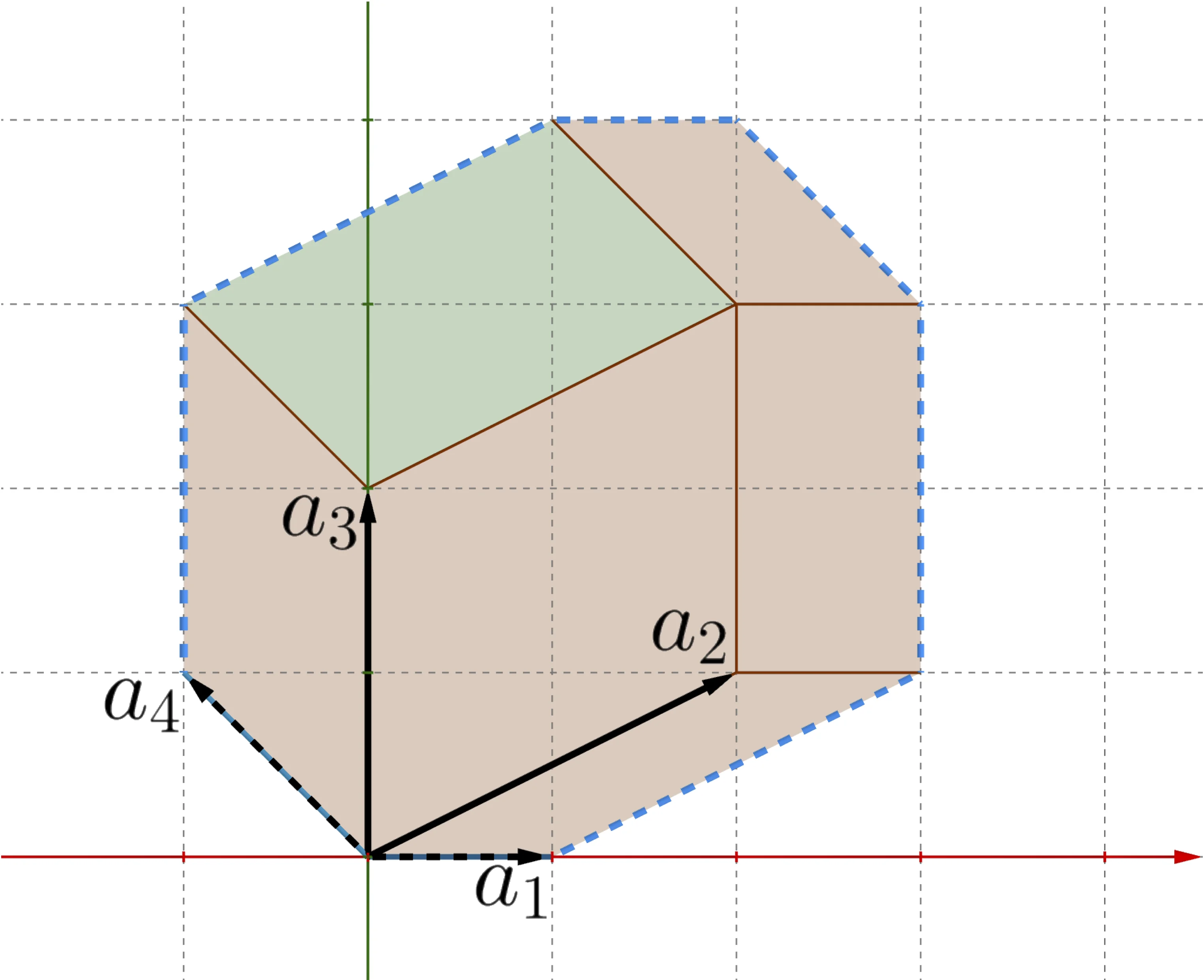
Determinantal point processes are the natural probabilistic model for diverse subset selection. The probability of a subset is the determinant of a kernel submatrix, so items that are similar (high kernel value) are pushed apart, and items that are different are pulled in together. DPPs are beautiful, generalize naturally to continuous spaces and Markov chains, and would be everywhere in machine learning if not for one bottleneck, sampling. Exact DPP sampling from an n-element ground set classically costs O(n³) for the eigendecomposition. This project rebuilds DPP sampling from scratch. We give the first exact DPP sampler with sublinear preprocessing (after a one-time cost, every sample comes out in sub-linear time), zonotope hit-and-run for projection DPPs that avoids the eigendecomposition entirely, fast samplers for continuous DPPs and β-ensembles via random matrix theory, and applications to Monte Carlo integration where the determinantal repulsion provably reduces variance. DPPy, our Python toolbox, packages this stack into a single library and has become the de-facto reference for DPP sampling in the community.
- Exact DPP sampling with sublinear preprocessing (NeurIPS 2019): first exact sampler whose per-sample cost is sublinear in the ground-set size
- Zonotope hit-and-run for projection DPPs (ICML 2017): MCMC sampling that avoids eigendecomposition entirely
- Two-step DPP sampling and continuous DPPs (NeurIPS 2019): fast samplers via Cholesky-like decompositions
- Fast β-ensemble sampling (Statistics and Computing 2021): random-matrix-theory-based samplers for general β-ensembles
- DPPy (JMLR 2019): the de-facto Python library for DPP sampling (500+ GitHub stars), packages exact, MCMC, and continuous samplers
- Sampling for Monte Carlo integration (NeurIPS 2020): provable variance reduction via determinantal repulsion
Combinatorial Bandits and Influence Maximization Completed
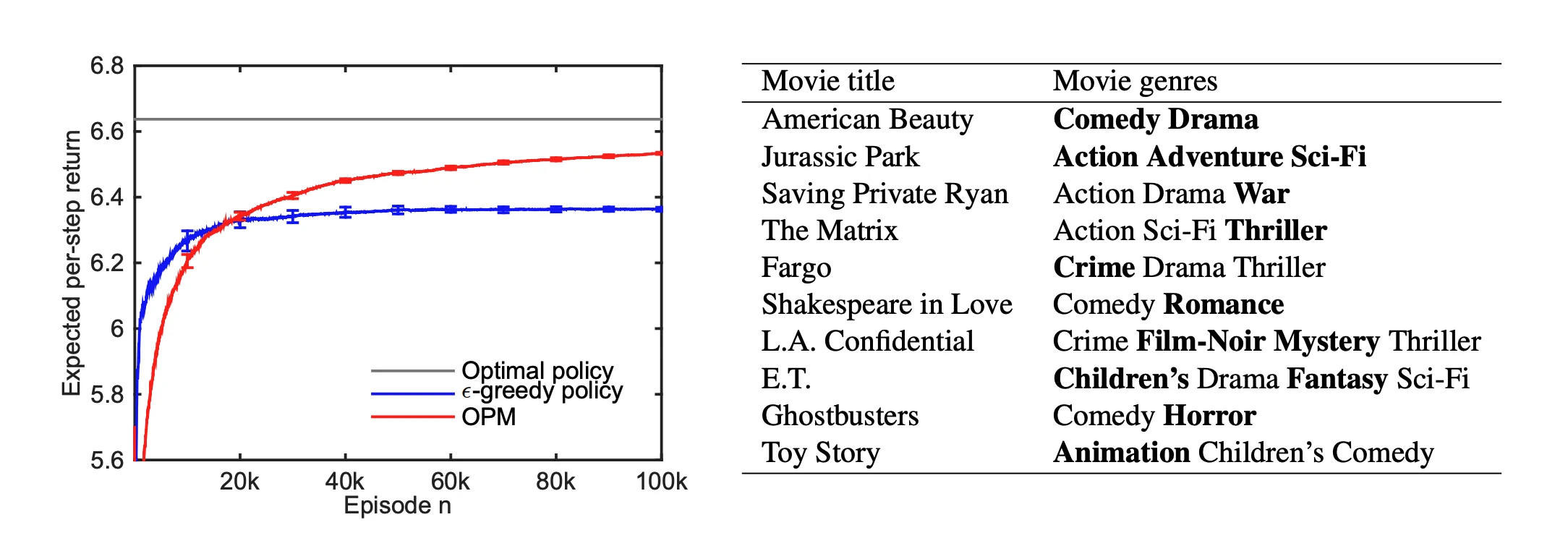
In combinatorial bandits, the learner pulls not a single arm but a structured subset (a path, a matching, a seed set in a graph) and gets feedback about each individual element. The flagship application is online influence maximization, where one asks which k users to seed in a social network to maximize the eventual cascade, when the diffusion probabilities are unknown and have to be learned by repeatedly seeding. Our line of work answers that under the independent-cascade model with semi-bandit feedback, then extends it to budgeted variants where seeding different users has different costs, matroid semi-bandits where the feasible subsets form a matroid (covering scheduling, assignment, and spanning-tree problems), and polymatroid settings. A parallel theoretical thread sharpens Thompson sampling, giving the first statistical-efficiency guarantees for Thompson sampling on combinatorial semi-bandits and design covariance-adapting algorithms that exploit dependence between arms rather than treating them as independent. The result is a unified toolkit for online combinatorial optimization with regret bounds that match the problem''s actual structural complexity, not the worst-case combinatorial blow-up.
- Online influence maximization under the independent cascade model (NeurIPS 2017): semi-bandit feedback, regret bounds that scale with the diffusion structure
- Budgeted online influence maximization (ICML 2020): per-seed budgets with regret guarantees
- Exploiting structure of uncertainty in matroid semi-bandits (ICML 2019): regret bounds that adapt to the matroid's rank and correlation structure
- Statistical efficiency of Thompson sampling for combinatorial semi-bandits (NeurIPS 2020): the first matching upper-bound guarantees for combinatorial TS
- Covariance-adapting algorithms for semi-bandits (COLT 2020): exploit arm dependence to beat independent-arm analyses
- Learning to act greedily in polymatroid settings (JMLR): greedy as a near-optimal online algorithm for polymatroid feasibility
Past Projects
Adaptive Structural Sampling Completed
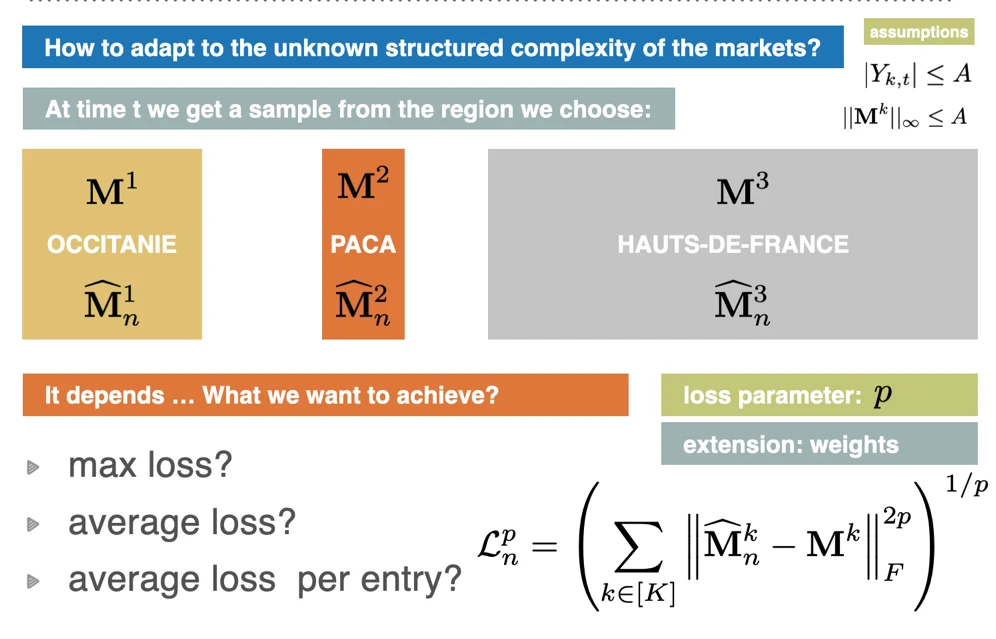
Many of the sequential problems require adaptive sampling in some particular way. Examples include using learning to improve rejection rate in rejection sampling, sampling with two contradictory objectives such as when we have to trade off reward and regret, extreme and infinitely many-arm bandits, and efficient sampling of determinantal point processes.
SQUEAK: Online Sparsification of Kernels and Graphs Completed
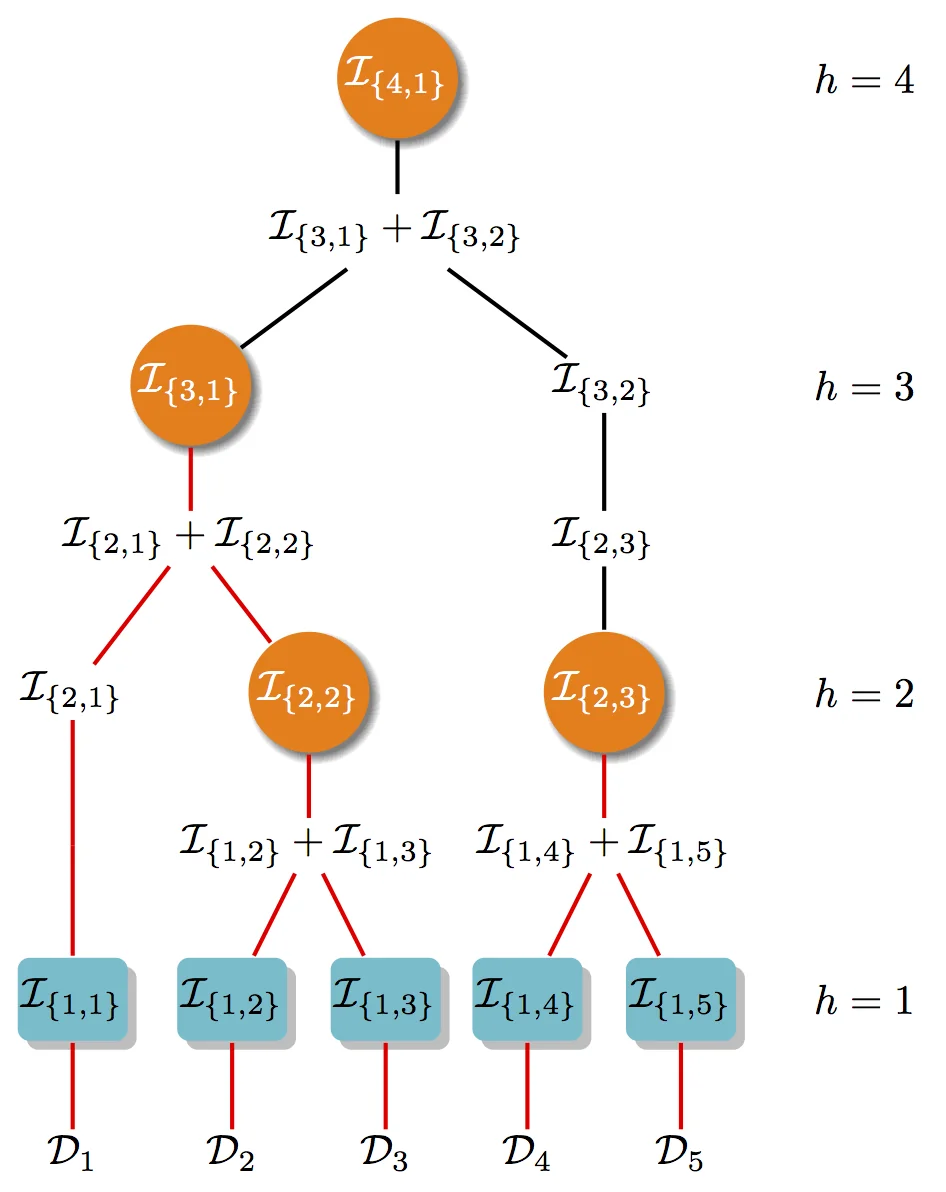
My PhD thesis ended with an open direction, whether efficient spectral sparsifiers can fuel online graph-learning methods. We introduce the first dictionary-learning streaming algorithm that operates in a single-pass over the dataset. This reduces the overall time required to construct provably accurate dictionaries from quadratic to near-linear, or even logarithmic when parallelized.
Graph Bandits Completed
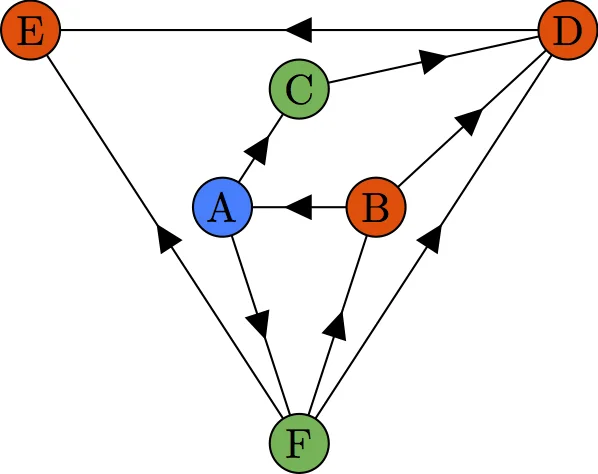
Bandit problems are online decision-making problems where the only feedback given to the learner is a (noisy) reward of the chosen decision. We study the benefits of homophily (similar actions give similar rewards) under the name spectral bandits, side information (well-informed bandits), and influence maximization (IM bandits). In the algorithms, we take advantage of these similarities in order to (provably) learn faster.
Semi-Supervised Apprenticeship Learning Completed
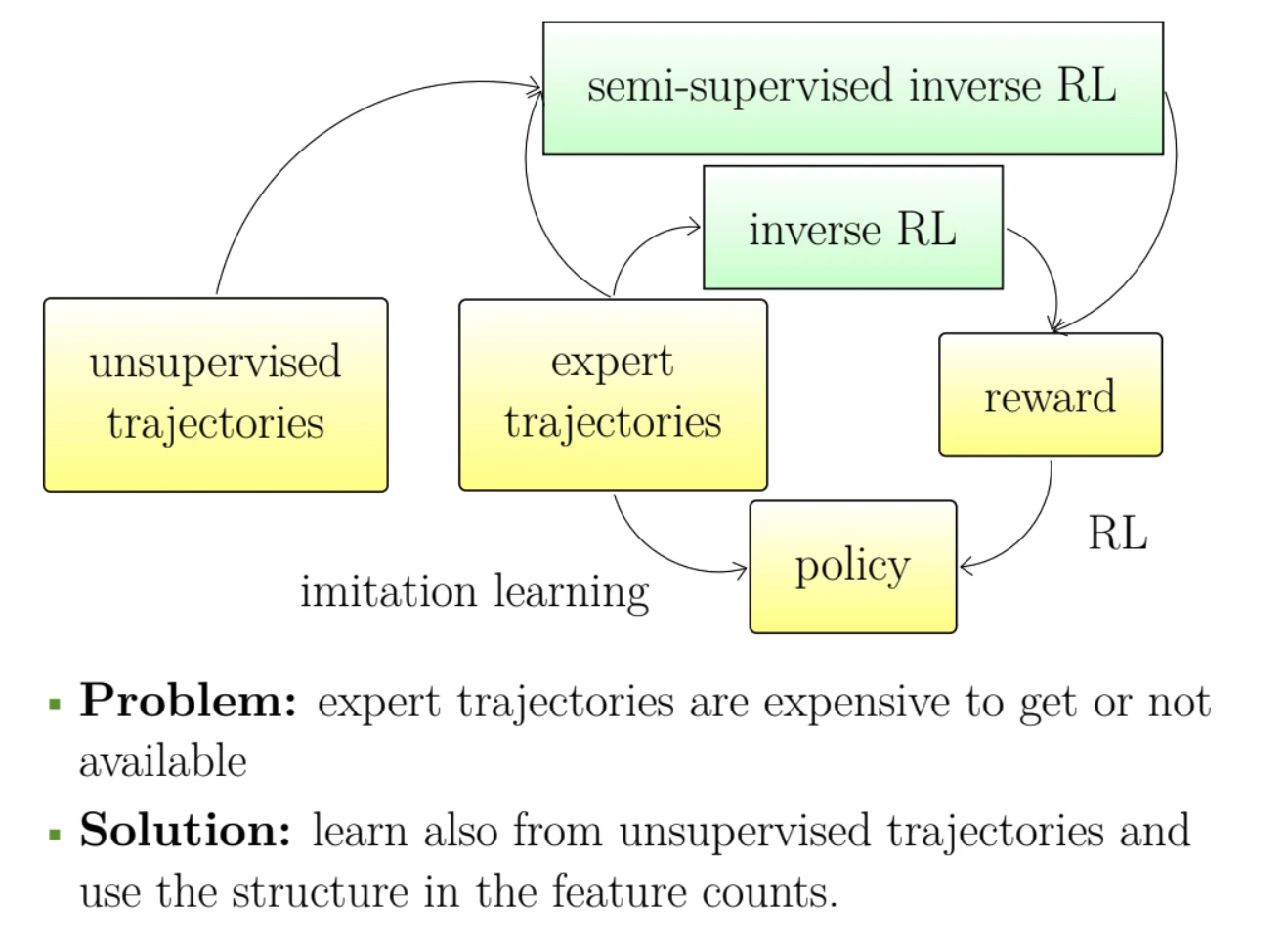
In apprenticeship learning we aim to learn a good behavior by observing an expert. We consider a situation when we observe many trajectories of behaviors but only one or a few of them are labeled as experts' trajectories. We investigate the assumptions under which the remaining unlabeled trajectories can aid in learning a policy with a good performance.
CompLACS: Composing Learning for Artificial Cognitive Systems Completed
The purpose of this project was to develop a unified toolkit for intelligent control in many different problem areas. This toolkit incorporates many of the most successful approaches to a variety of important control problems within a single framework, including bandit problems, Markov Decision Processes (MDPs), Partially Observable MDPs (POMDPs), continuous stochastic control, and multi-agent systems.
Large-Scale Semi-Supervised Learning Completed

We parallelized online harmonic solver to process 1 TB of video data in a day. I am working on the multi-manifold learning that can overcome changes in distribution. I am showing how the online learner adapts as to characters' aging over 10 years period in Married... with Children sitcom. The research was part of Everyday Sensing and Perception (ESP) project.
Online Semi-Supervised Learning Completed

We extended graph-based semi-supervised learning to the structured case and demonstrated on handwriting recognition and object detection from video streams. We came up with an online algorithm that on the real-world datasets recognizes faces at 80-90% precision with 90% recall.
Anomaly Detection in Clinical Databases Completed
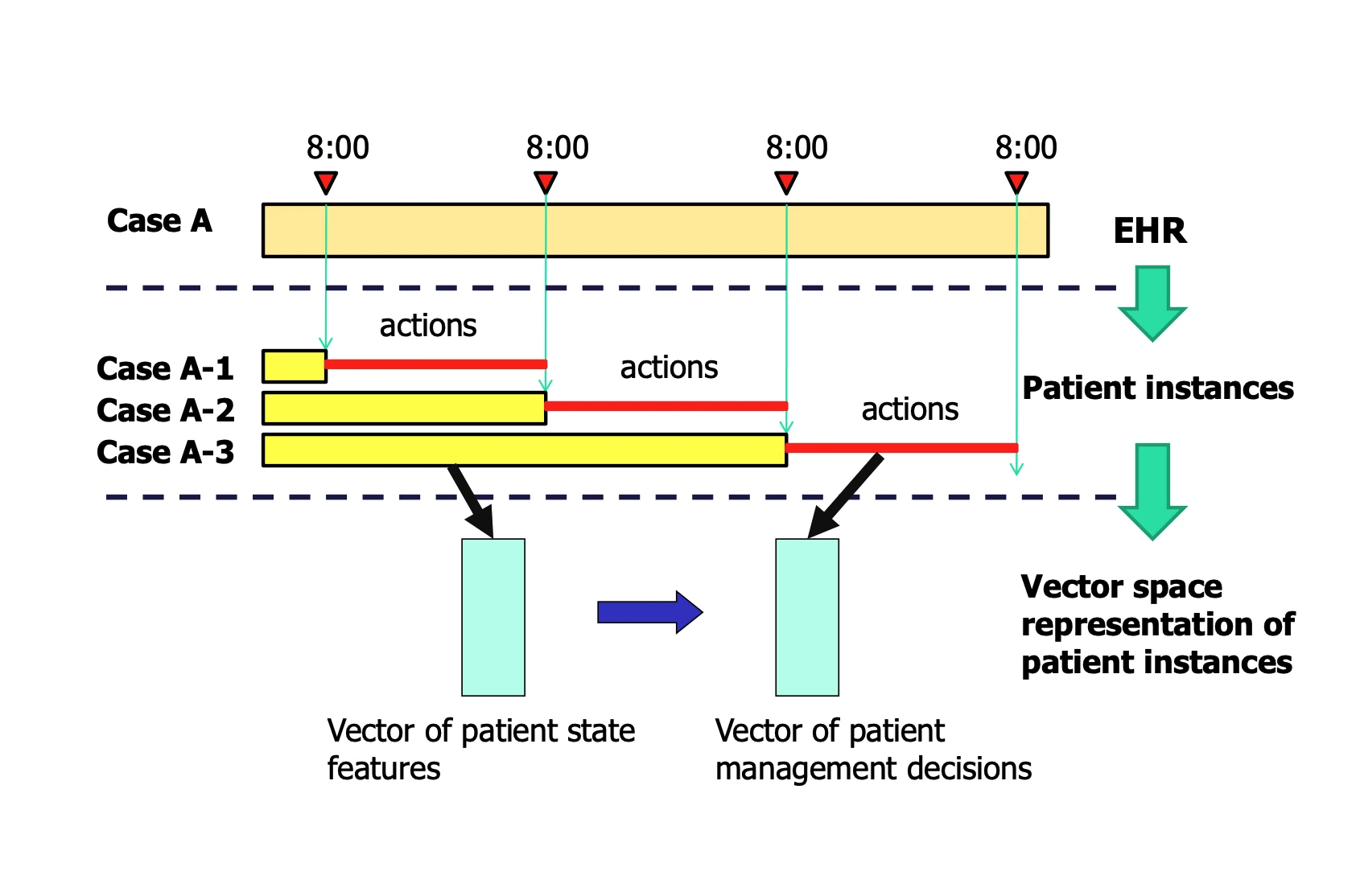
Statistical anomaly detection methods for identification of unusual outcomes and patient management decisions. I combined max-margin learning with distance learned to create an anomaly detector, which outperforms the hospital rule for Heparin Induced Thrombocytopenia detection. I later scaled the system for 5K patients with 9K features and 743 clinical decisions per day.
Odd-Man-Out Completed
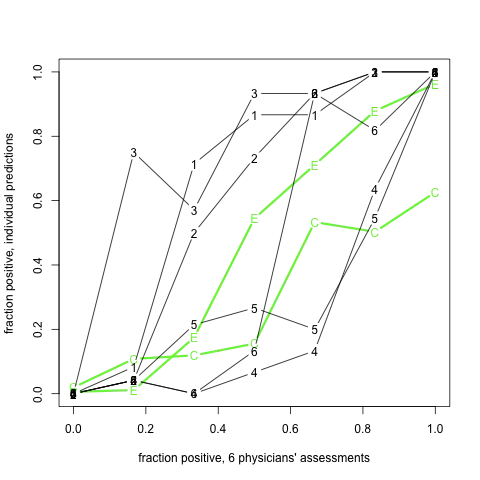
We hypothesized that clinical data in emergency department (ED) reports would increase sensitivity and specificity of case identification for patients with an acute lower respiratory syndrome (ALRS). We designed a statistic of disagreement (odd-man-out) to evaluate the machine learning classifier with expert evaluation in the cases when the gold standard is not available.
High-Throughput Proteomic and Genomic Biomarker Discovery Completed
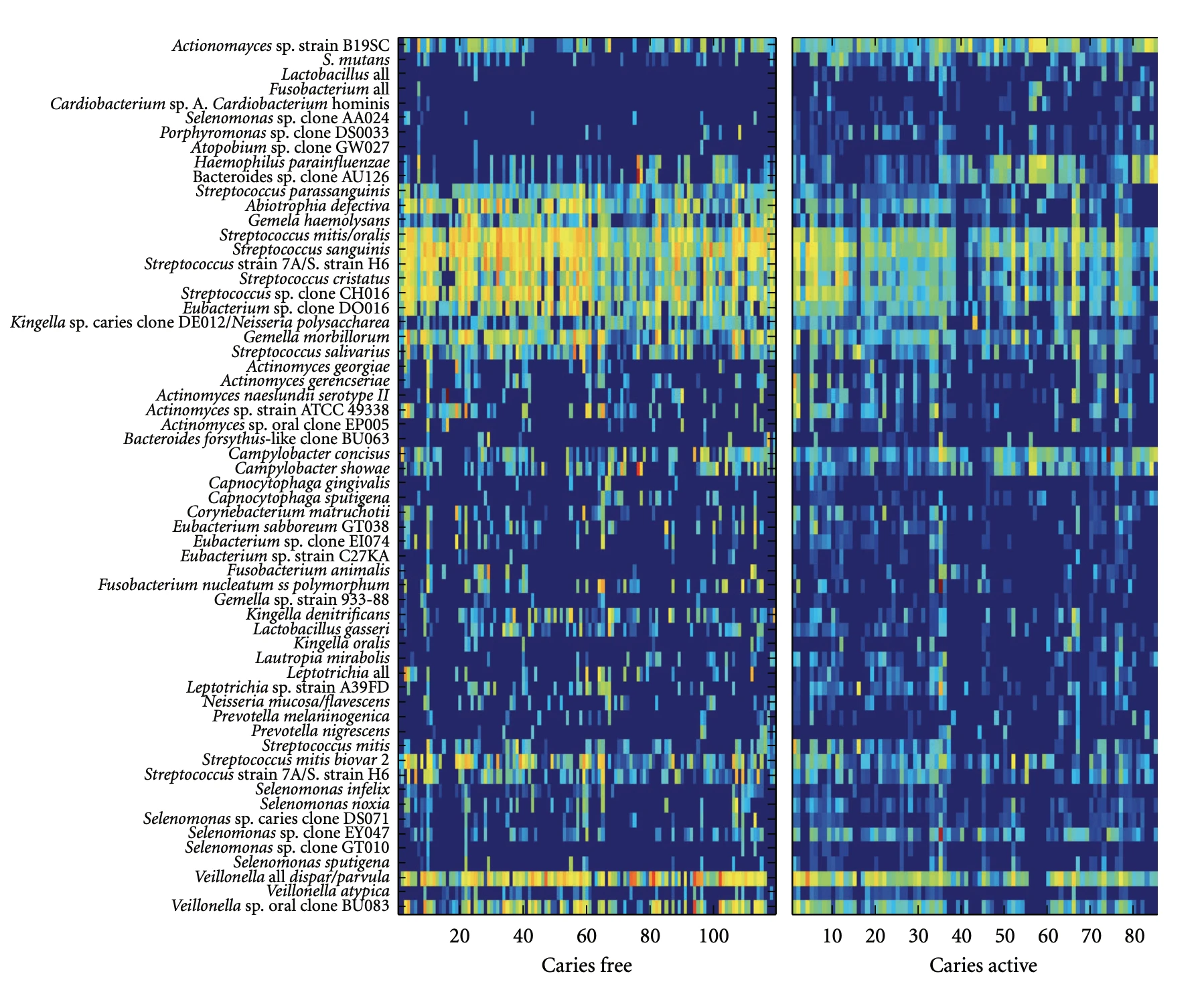
I built a framework for the cancer prediction from high-throughput proteomic and genomic data sources. I found a way to merge heterogeneous data sources: My fusion model was able to predict pancreatic cancer from Luminex combined with SELDI with 91.2% accuracy.
Archive
Evolutionary Feature Selection Algorithms Completed

We enhanced the existing FeaSANNT neural feature selection with spiking neuron model to handle inputs noised with up to 10% Gaussian noise.
Plastic Synapses (Regularity Counting) Completed
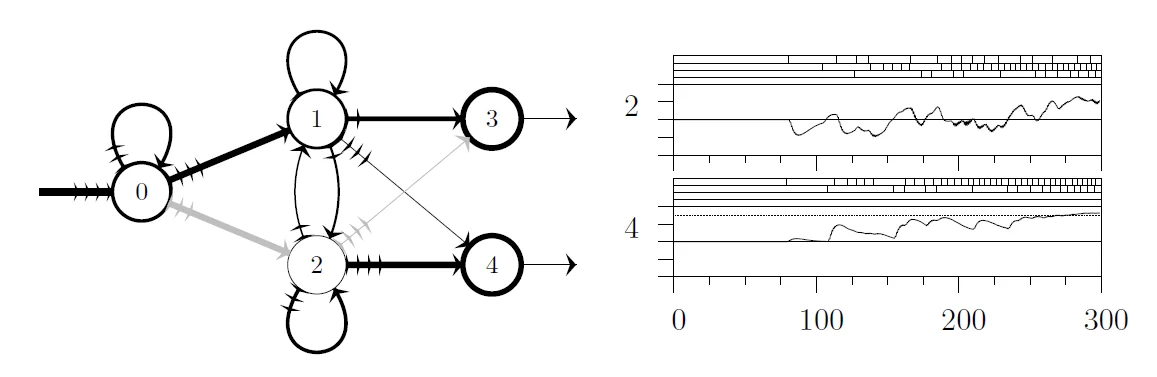
We were modeling basic learning function at the level of synapses. I designed a model that is able to adapt to the regular frequencies with different rate as the time flows. I used genetic programming to find biologically plausible networks that distinguish different gamma distribution and provided explanation of the strategies evolved.
Algebraic Structures Completed

Implementation of algebraic structures hierarchy (groups, rings, fields) in Smalltalk. Features modular arithmetic didactic tools, RSA encryption demonstration, and primality testing. A university course project exploring OOP design patterns.
Double Dispatching Completed
An explanation of the Double Dispatching design pattern in Smalltalk. This OOP technique elegantly solves polymorphism with parameters by reducing uncertainty step-by-step through secondary method dispatch, replacing conditional constructs with robust polymorphic code.
Pexeso (Voice-Controlled Memory Game) Completed

A memory matching game for children with voice control capability. Built with GTK on Linux, featuring custom speech recognition using HTK. Includes Finding Nemo and Flags card sets. Presented at a school for gifted children in Bratislava.
Wget Presentation Completed
A presentation (in Slovak) about GNU Wget - the powerful non-interactive command-line tool for downloading files via HTTP, HTTPS, and FTP. Covers resume, mirroring, recursive downloads, proxy support, and configuration tips.
ŠKAS - Student Council Work Completed
Work as a member of the Student Chamber of the Academic Senate (ŠKAS) at FMFI UK. Successfully advocated for changes to study regulations: flexible credit requirements for final year students, guaranteed 5-week exam period, removal of prerequisites as hard blocks, and student-friendly policies.
University Coursework Archive Completed
2000 – 2005Collection of course assignments and projects from Comenius University (FMFI UK). Includes work on CORDIC algorithms, game theory (prisoner's dilemma), Hilbert's program, computational linguistics, neurocomputing simulations, neural networks, and more.
Concross - Consonant Crosswords Completed
A Delphi application for creating and solving consonant crossword puzzles (spoluhláskové krížovky). Features puzzle creation mode, solving interface, and educational value for language learning.
HTML Editors Review Completed

A review of HTML editors and web development tools from the late 90s, including Macromedia Dreamweaver 3, CoffeeCup, HotDog, and others. Compares WYSIWYG vs. code-based approaches to web design.
How to Tie Ties Completed

A visual step-by-step guide to tying three classic tie knots: Manhattan (Four-in-Hand), Windsor, and Butterfly (Bow Tie). Created as one of my first web projects.
Miscellaneous Completed

A collection of miscellaneous personal content: travels around Europe and USA, sports at Pitt CS department (volleyball & basketball), movie tracker, mystery postcards, legacy images, old portrait photos, and project logos from the early web days.
Music Collection Completed

Archive of my music collection from the early 2000s, featuring R.E.M. albums (from Murmur to Reveal), Jaromír Nohavica, Édith Piaf, and various singles including Queen, Offspring, and Pink Martini.
SOČ: Internet Completed

High school research project (SOČ - Stredoškolská odborná činnosť) about the Internet, written in Slovak. Covers Internet basics, protocols (TCP/IP, DNS), network services (email, Telnet, FTP, WWW), and the social impact of the Internet in the late 1990s.
Splash! Completed

A nostalgic 90s-style internet splash page featuring original artwork. A snapshot of early web aesthetics and personal expression from the dial-up era.
Slovak Math & Physics Competitions Archive Completed

Archive of Slovak mathematical and physics competition materials from high school years. Contains problem sets, solutions, and seminar materials from 1999-2002.
SKMS Website Completed
Website for Stredoslovenský korešpondenčný matematický seminár (Central Slovak Correspondence Math Seminar). Features interactive star rating system and seminar archives.
Oktava2000 Discussion Forum Completed

PHP-based discussion forum and community platform created during high school years. Features debate system, user management, and custom styling. Archive preserves messages from 2003 and group collage.